- 社交网络与文本分析课程
1 文本分析概述
刘跃文 教授、博导西安交通大学 管理学院
联系方式: liuyuewen@xjtu.edu.cn2023年5月16日 版本1.3
提纲¶
- 什么是文本分析
- 文本分析的基本流程
- 常见的文本分析任务
- 各种应用方向举例
- 文本分析的基本思路
- 语料与数据化
1. 什么是文本分析?¶
- 文本是非数字类数据的一种(类似的还有图像、声音、视频)
- 历史上由于手段限制,主要是对数字类数据进行了分析和利用。
- 非数字类的数据利用存在几大困难
- 难以定量化
- 总信息量过大,人工分析难以承受
- 次要信息难以压缩,有效信息难以提取
- 难以纳入数学分析框架
- 所谓文本分析就是:想办法对文本这种数据加以利用!
- 从大量文本数据中抽取隐含的、未知的、可能有用的信息。
- 也被称为文本挖掘、自然语言处理(NLP)
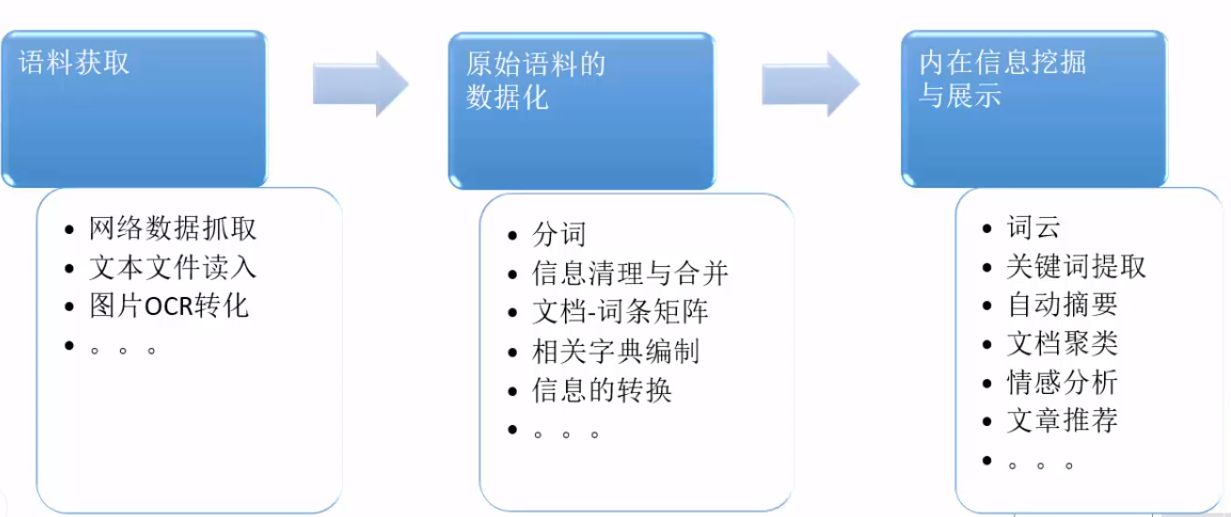
2. 文本分析的基本流程¶
- 语料获取:网络数据抓取、文本文件读入、图片OCR转化……
- 原始语料的数据化:分词、信息清理与合并、文档-词条矩阵、相关字典编制……
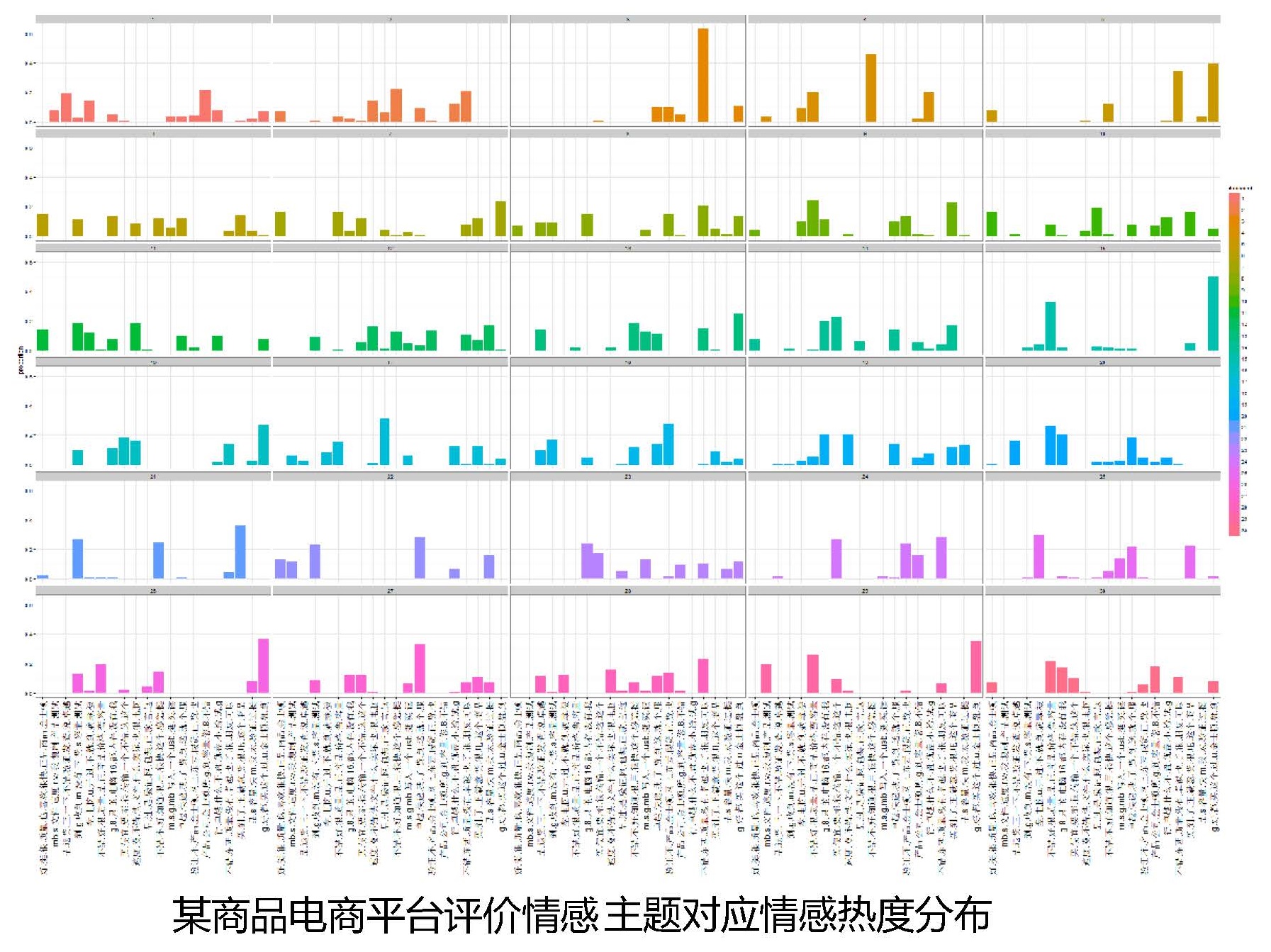
- 内在信息挖掘与展示:词云、关键词提取、自动摘要、文档聚类、情感分析、文章推荐……
3. 常见的文本挖掘任务¶
- 亚洲语言分词
- 自动摘要
- 指代消解
- 他对她说它的尾巴很短
- 机器翻译
- 词性标注
- 主题识别
- 文本分类
- 语义理解
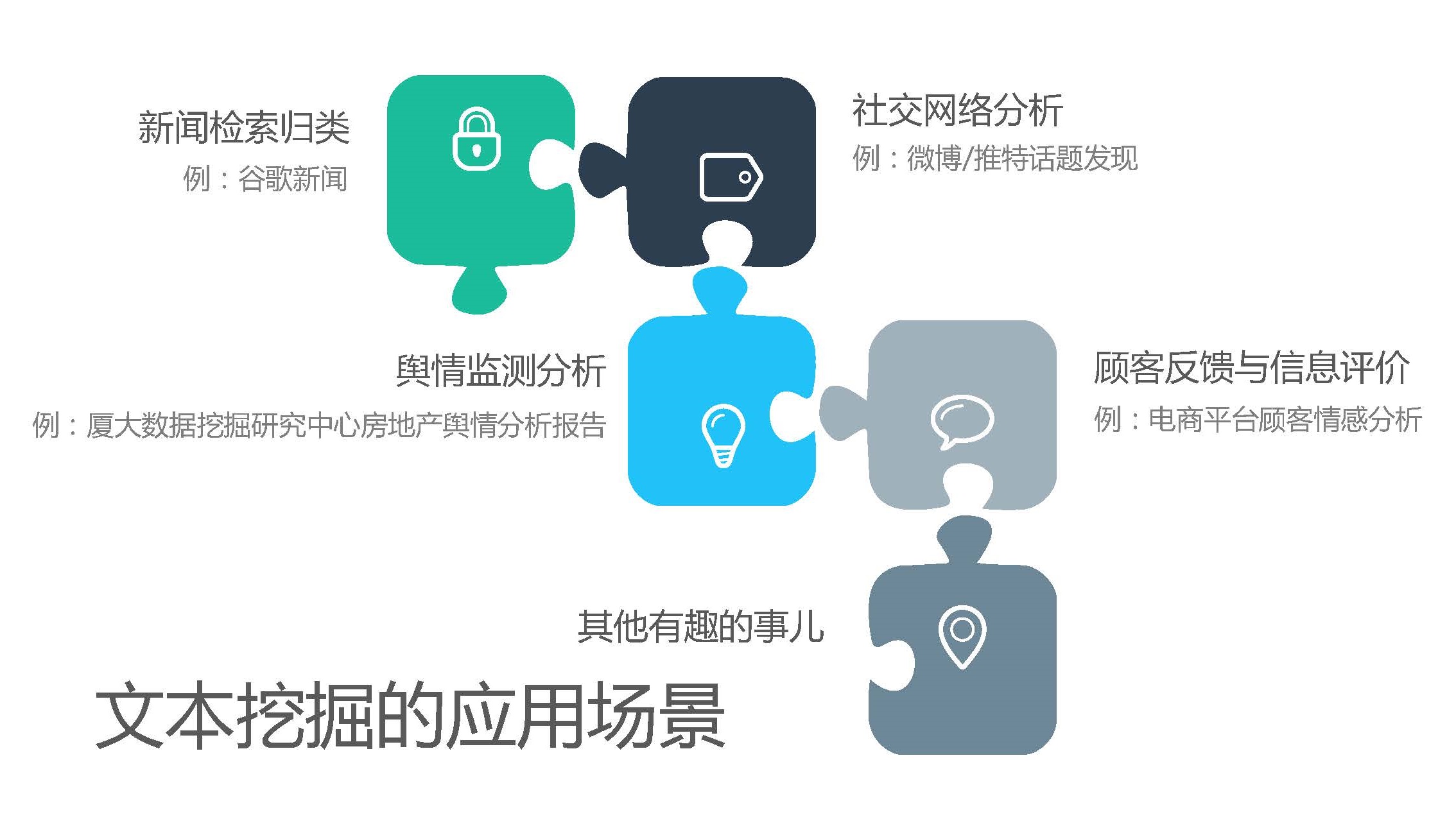
4 各种应用方向举例¶
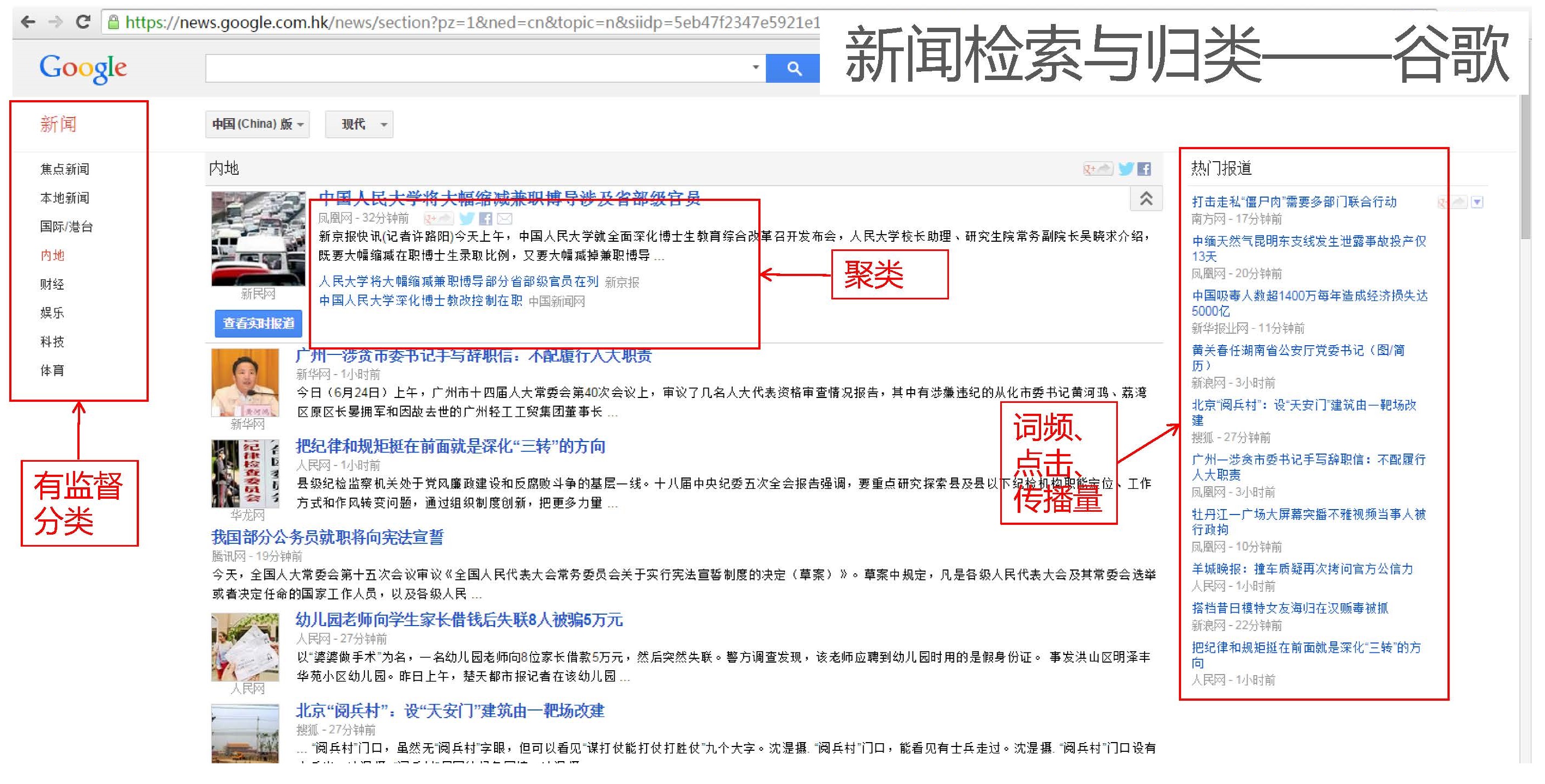
- 新一代搜索引擎
- 某博热搜榜
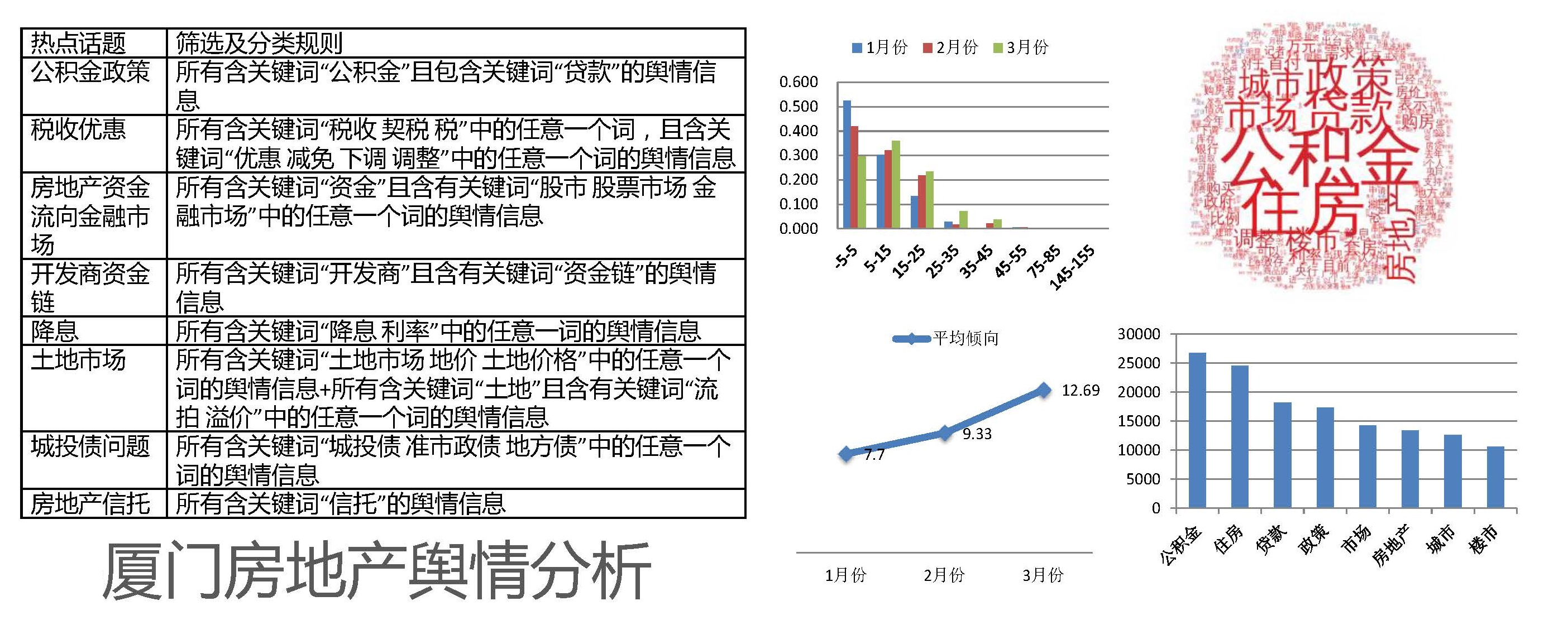
- 互联网内容安全
- 互联网舆情监测、非法内容发布审核
- 企业知识管理
- 企业内知识共享、企业相关外部信息
- 个人智能信息访问
- 目标客户的精确定位和推送
- ……
- 以下内容来自 Datartisan 刘晓葳 课件
- 自动词语关联


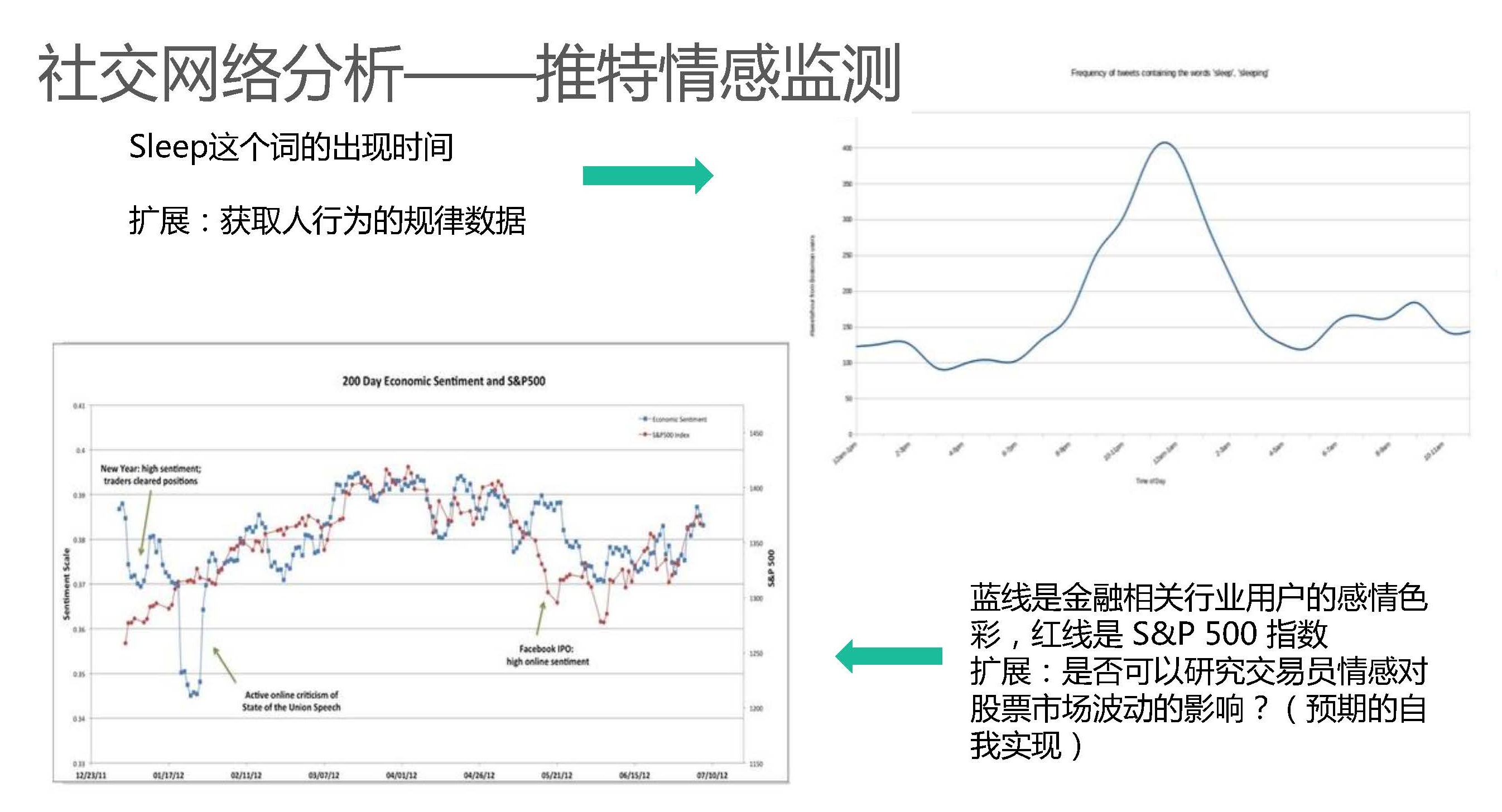
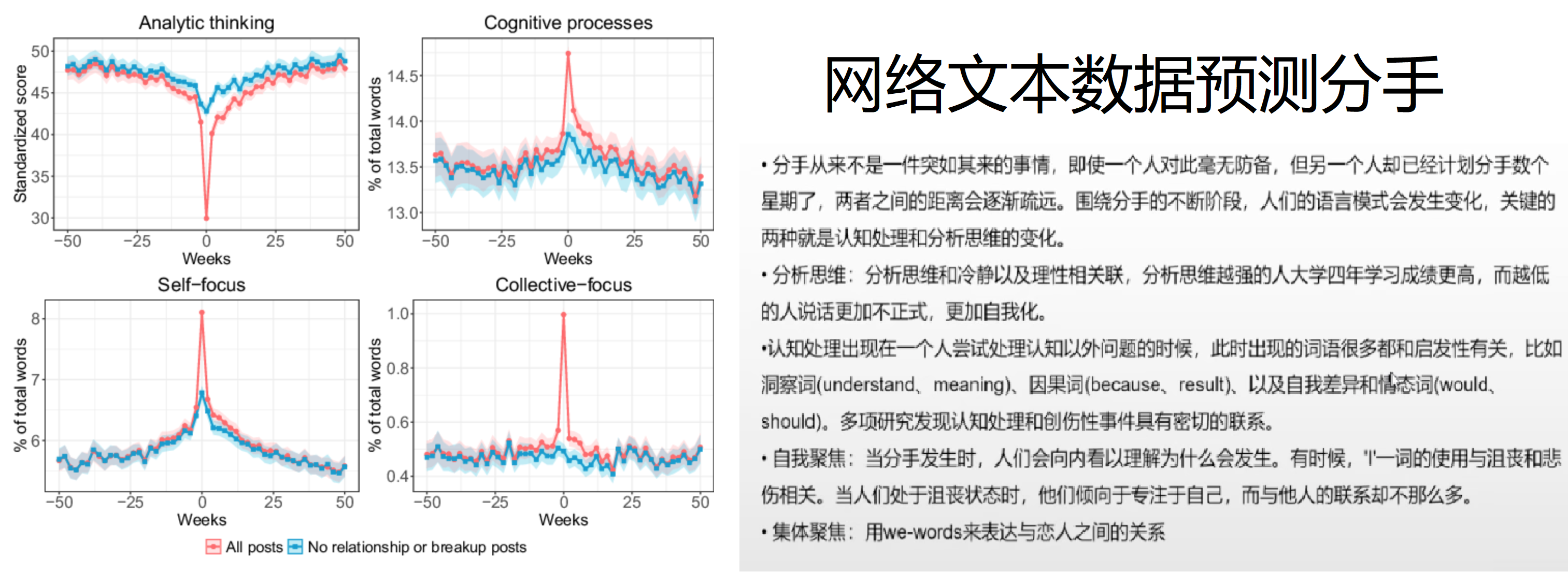
- paper: https://www.pnas.org/content/118/7/e2017154118 All the Reddit datasets used in this study are publicly available at Submissions: https://files.pushshift.io/reddit/submissions/
- 一个写中文古诗的网站 http://jiuge.thunlp.org/

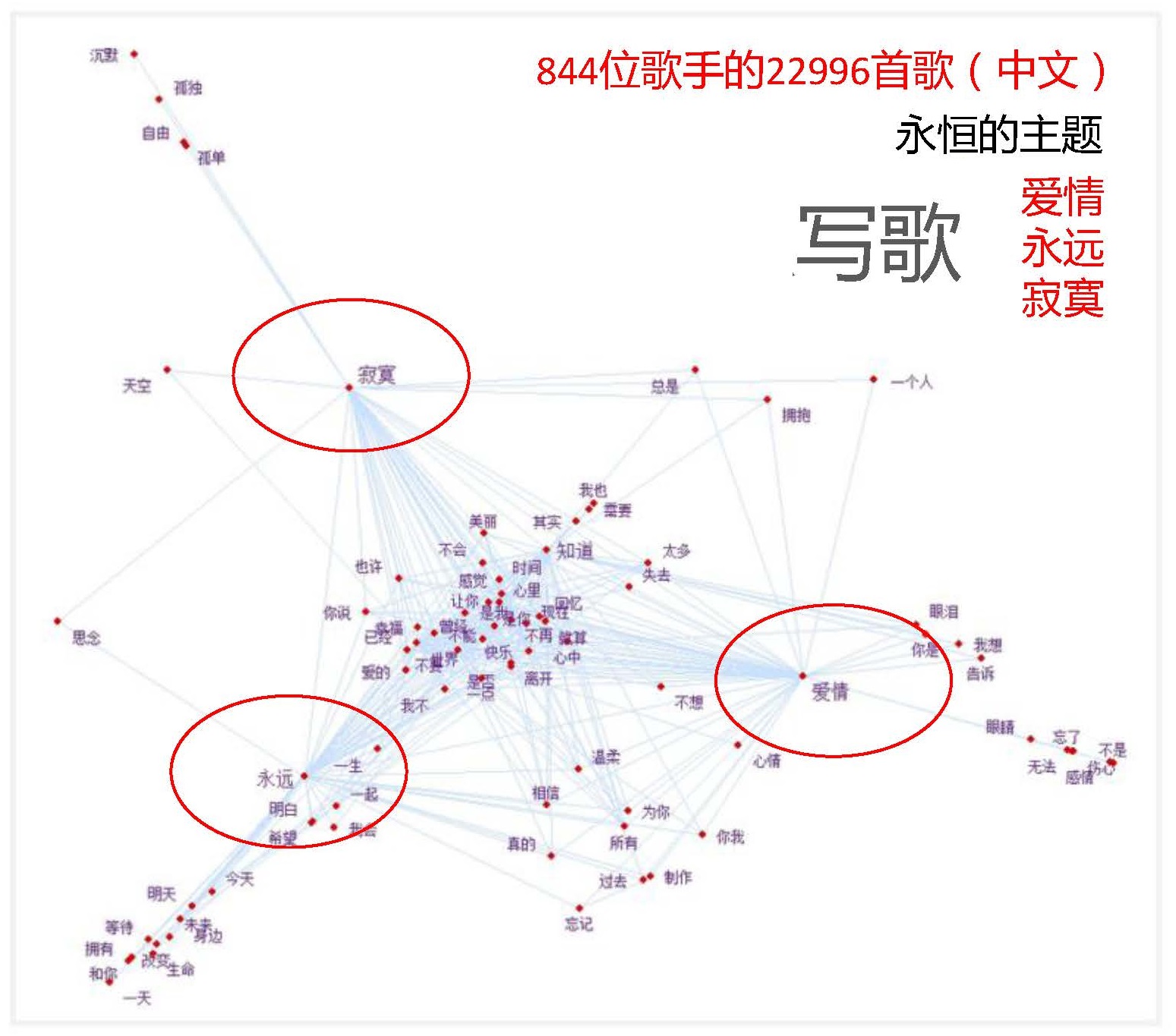
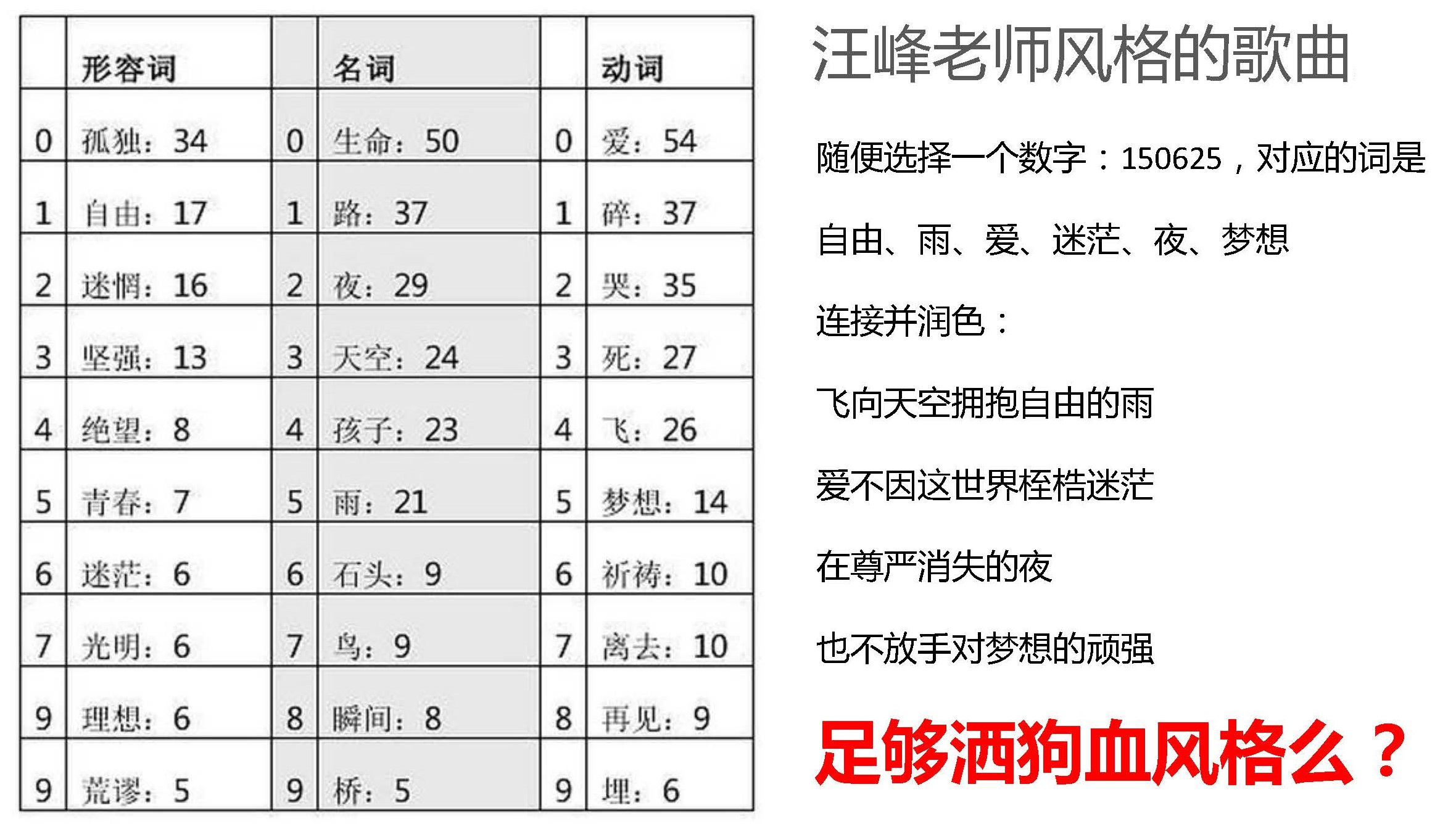
5.2 两大基本思路¶
- 传统:基于字典/语言学家
- 不能分辨细节差异
- 需要大量人为劳动
- 结果主观,依赖于编制者的经验和倾向
- 无法发现新词
- 难以精确计算词之间的相似度
- 现代:基于统计模型
- 特征提取:对语料进行各种可能的重编码和组合,尽可能的将信息数量化
- 用模型对潜在信息进行提取建模
6 原始语料数据化时需要考虑的工作¶
- 基本目的:将语料数据化的同时尽可能地保留有效信息
- 分词:将原始文本拆分为有分析意义的最小信息单位
- 中文由于信息效率太高,在这方面存在很大障碍
- 去除停用词:剔除无意义单词,减少无效信息
- 去除空白,去除标点符号等
- 词根识别:主要针对拉丁语系,中文不存在时态变化,基本无此问题
- 大小写转换
- 同义词/近义词识别:很多工具都缺少这一部分功能
- 术语识别:姓名识别、地理名称识别、专用名词识别等
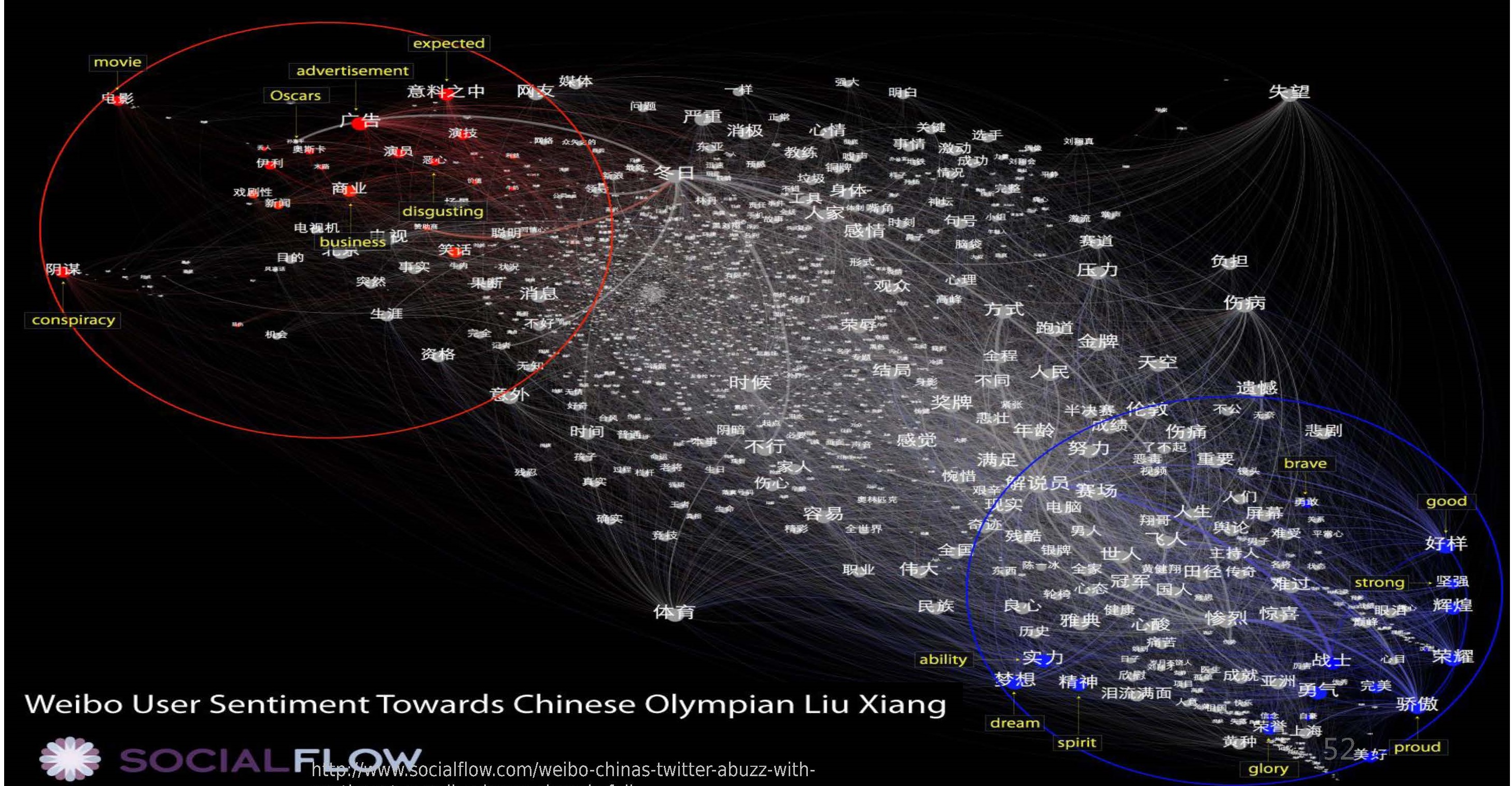
- 情感标注
- 词性标注:按照名词、动词、副词等进行标注
- 中文的词性标注要复杂得多:张编辑在编辑;他一把把把把住了。
- 语法分析
- 语义分析
- 他差点儿被吓死/他差点儿没被吓死
- 中国队大胜日本队/中国队大败日本队
- 自然语言处理(NLP)的发展历程
- 早期自然语言处理: 第一阶段(60~80年代):基于规则来建立词汇、句法语义分析、问答、聊天和机器翻译系统。好处是规则可以利用人类的内省知识,不依赖数据,可以快速起步;问题是覆盖面不足,像个玩具系统,规则管理和可扩展一直没有解决。
- 统计自然语言处理: 第二阶段(90年代开始):基于统计的机器学习(ML)开始流行,很多NLP开始用基于统计的方法来做。主要思路是利用带标注的数据,基于人工定义的特征建立机器学习系统,并利用数据经过学习确定机器学习系统的参数。运行时利用这些学习得到的参数,对输入数据进行解码,得到输出。机器翻译、搜索引擎都是利用统计方法获得了成功。
- 神经网络自然语言处理: 第三阶段(2008年之后):深度学习开始在语音和图像发挥威力。随之,NLP研究者开始把目光转向深度学习。先是把深度学习用于特征计算或者建立一个新的特征,然后在原有的统计学习框架下体验效果。比如,搜索引擎加入了深度学习的检索词和文档的相似度计算,以提升搜索的相关度。自2014年以来,人们尝试直接通过深度学习建模,进行端对端的训练。目前已在机器翻译、问答、阅读理解等领域取得了进展,出现了深度学习的热潮。
- Qian Li, Hao Peng, Jianxin Li, Congying Xia, Renyu Yang, Lichao Sun, Philip S. Yu, Lifang He, 2021, A Survey on Text Classification: From Shallow to Deep Learning, ACM Trans on Intelligent System Technology download

语料数据化中保留的信息量决定了随后建模分析所能达到的最终高度!
谢谢大家!