- 社交网络与文本分析课程
6 网络生成模型
刘跃文 教授、博导西安交通大学 管理学院
联系方式: liuyuewen@xjtu.edu.cn2023年5月9日 版本1.3
引言¶
为什么要模拟实际的网络?
如何模拟出实际的网络?
实际网络是怎么样的?
- 度分布——通常满足幂律分布
- 聚类系数——实际网络的聚类系数较高
- 平均路径长度——实际网络的平均距离普遍较短
- 我们的工作
- Yuewen Liu, Ke Xu, Xiangyu Chang*, Dehai Di, Wei Huang, (2018), Social network analysis based on canteen transaction records, Statistics and Its Interface, 11(1), Pages 191-200. Download
- 问题:共同吃几次饭,才算是好友?
- 对比观察到的网络和生成的网络
提纲¶
- 规则网络
- 随机网络
- 小世界网络
- 无标度网络
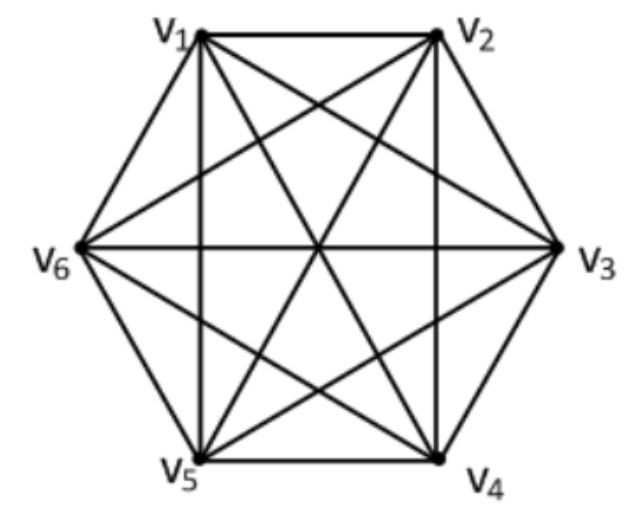
- 性质
- 度分布:各节点的度均为$N-1$
- 聚类系数:每个节点的聚类系数均为1,故整个网络的聚类系数为1
- 平局路径长度:从任意一个节点到另外一个节点最短路径长度都为1,故整个网络的平均距离为1
- 评价
- 在具有相同节点数的所有网络中,完全链接网络具有最小的平均距离和最大的聚类系数。
- 该模型作为实际网络模型的局限性很明显:完全链接网络是最稠密的网络,然而大多数实际网络都是很稀疏的
1.2 最近邻居链接网络¶
- 对于拥有$N$节点的网络来讲,通常将每个节点只与它最近的$K$个节点连接的网络称为最近邻居链接网络,这里$K$是小于等于$N-1$的整数。
- 若每个节点只与最近的2个邻居节点相连,这样所有节点相连就构成了一维链或环,如下图(a)所示。
- 二维晶格也是一种最近邻居链接网络,如下图(b)所示。
- 一般情况下,一个具有周期边界条件的最近邻居网络包含N个围成一个环的节点,每个节点都与它左右各$K/2$个邻居节点相连,这里$K$是偶数,如下图(c)所示。
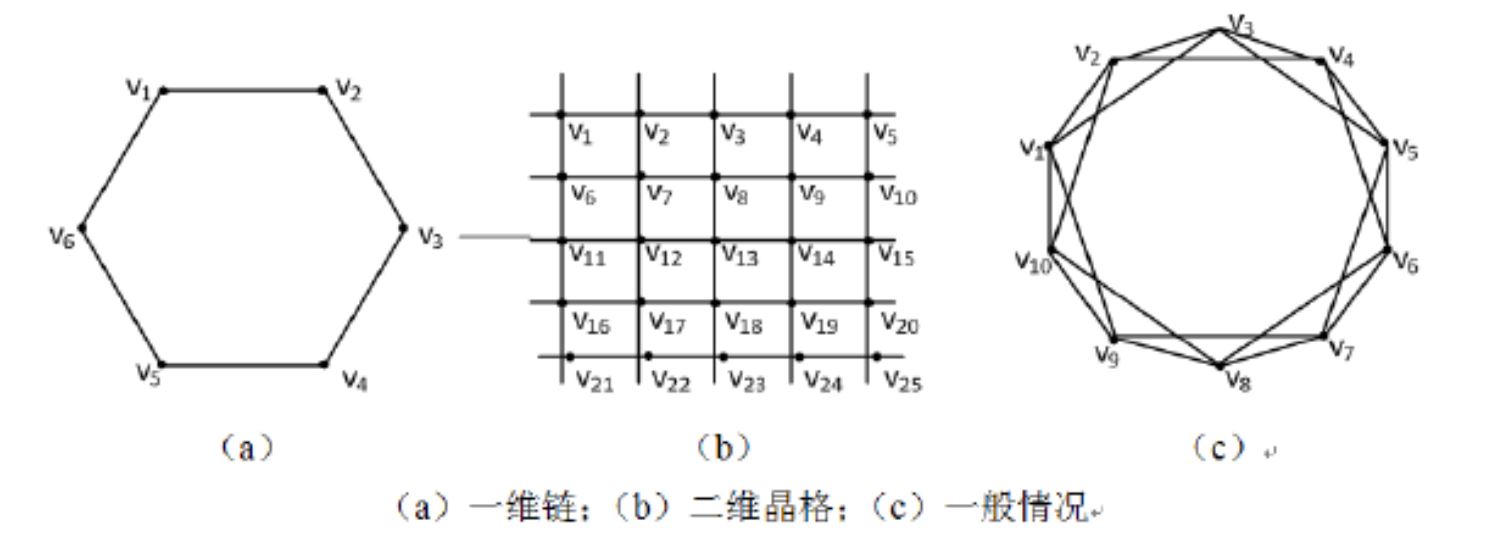
- 对于上述第三种情况:
- 性质
- 度分布: 每个节点的度均为$K$
- 聚类系数: 每个节点的聚类系数为$C=C_{i}=\frac{3\left (K-2 \right )}{4\left ( K-1 \right )}$
- 对较大的$K$值,容易得到$C\approx 0.75$
- 平均路径长度:对固定的K值,平均距离为$L\approx \frac{N}{2K}$
- 评价
- 集聚程度较高
- 平均距离较大
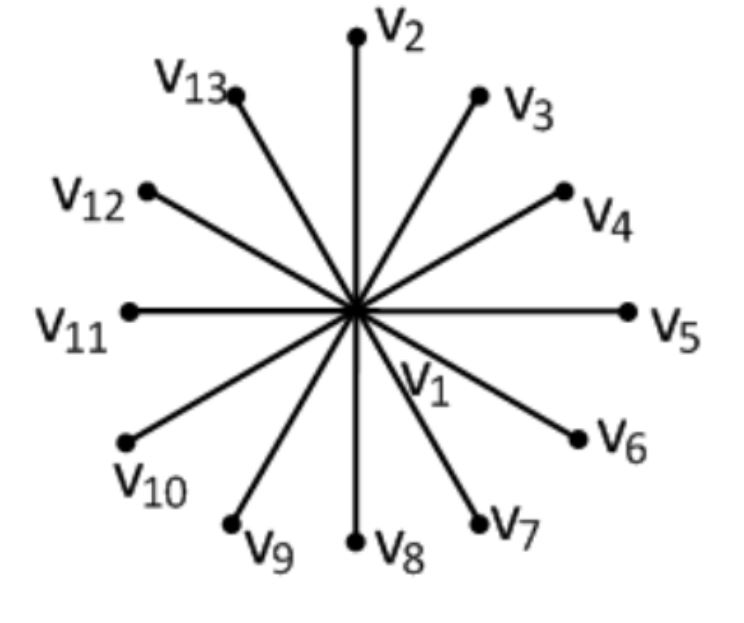
- 性质
- 度分布: 中心节点度为$N-1$, 而其他节点度均为1
- 聚类系数:假设定义一个节点只有一个邻居节点时,其聚类系数为1,则中心节点的聚类系数为0,而其余$N-1$个节点的聚类系数均为1。所以整个网络的平均聚类系数为$C=\frac{N-1}{N}$
- 平均路径长度?
- 评价
- 具有稀疏性、集聚性和小世界特性
2. 随机网络¶
2.1 什么是ER随机网络¶
- ER不是Entity-Relation,是ER随机图模型(Erdős–Rényi model)。其名字源于最早提出上述模型之一的数学家保尔·厄多斯(Paul Erdős)和阿尔弗烈德·瑞利(Alfréd Rényi)。
- 基本假设:节点之间的边是随机生成的
- 定义:一个随机网络(又称:随机图)是由$N$个节点构成并且每对节点之间的连接概率为$ p $
- 分类:
- $G\left ( N,p \right )$模型:一个随机图由 $N$个节点构成并且任意两个不同节点之间存在一条连边的概率为$p$
- $G\left ( N,L \right )$模型:一个随机图由 $N$个节点构成并且有$L$条连边随机放置在$L$对节点之间 (不出现重边和自环)
- 例:$G\left (N,p \right )$模型:
- 连边概率$ p=1/5 $;
- 节点数$ N=10 $;
- 例:$G\left ( N,L \right )$模型:
- 节点数$ N=10 $;
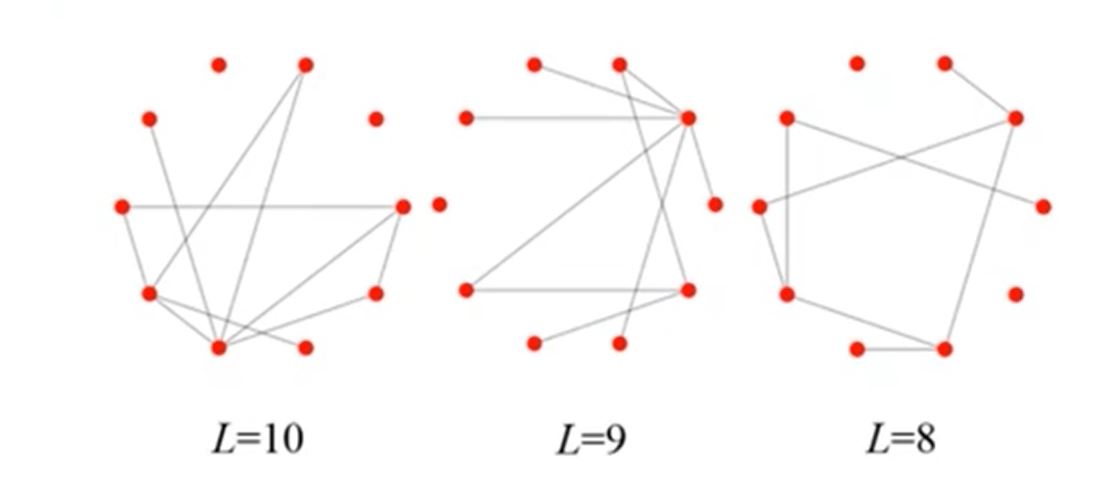
2.2 随机网络生成过程¶
- 随机图模型- $𝐺(N, 𝑝)$
- 假设一个图有固定数量的$N$个节点
- $\binom{N}{2}$条边中任意一条以$p$的概率,独立的进行连接
- 这样的图称为$𝐺(N, 𝑝)$随机图
- 显然,$𝐺(N, 𝑝)$随机图要进行$\binom{N}{2}$次连边实验
- 这个模型最早由Solomonoff and Rapoport(1951)、Edgar Gilbert (1959) 分别独立提出
- 随机图模型- $𝐺(N, L)$
- 假设图中有$N$个节点和$L$条边
- 需要确定应从$\binom{N}{2}$条可能的边中选择哪$L$条边
- 令$\Omega $为所具有$N$个节点和$L$条边的图的集合,则$\left | \Omega \right |=\binom{\binom{N}{2}}{L}$
- 为了生成一个随机图,可以以均等概率随机地在$\Omega $中选择一个图,每个图被选中的概率是$\frac{1}{\left | \Omega \right |}$
- 实际上,一种等价的易操作的方法是:从$\binom{N}{2}$条边进行不放回均匀抽样$L$次,只有抽中的可能边留下来称为真正的边
- $𝐺(N, L)$ 随机图模型由Paul Erdös和Alfred Rényi (1959)提出
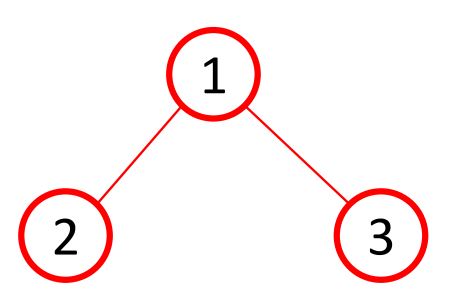
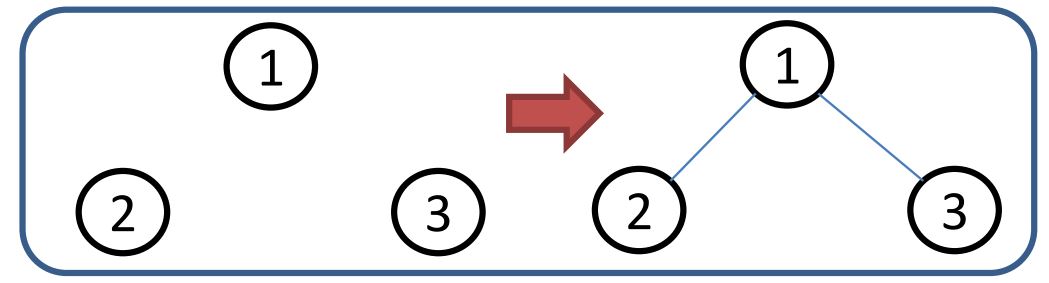
Example: 对于随机图模型$G(3,2)$
在第一种方法中,生成下图的可能性为$1/3$
其中$\Omega $集合中包含以下三个元素

- 而在第二种方法中,生成该图的概率也是 $1/3$
- $G(N,p)$ 和 $G(N,L)$的比较
- 相似之处
- 当$N$非常大时,模型$G(N,p)$ 和 $G(N,L)$是相似的
- 图 $G(N,p)$中边的期望数为$\binom{N}{2}p$
- 假设$\binom{N}{2}p=L$,在极限情况下,这两个模型是很相似的
- 当$N$非常大时,模型$G(N,p)$ 和 $G(N,L)$是相似的
- 不同之处
- 模型$G(N,L)$中边数为常数$L$
- 模型$G(N,p)$中边数是随机的,可能不包含边或者包含所有可能的边
- 模型$G(N,p)$中,连接到一个节点的边数的期望值是$c=(N-1)p$
- 边的期望值是$\binom{N}{2}p$
- 观察到$L$条边的概率服从二项分布$P\left ( \left | E \right |=L \right )=\binom{\binom{N}{2}}{L}p^{L}\left ( 1-p \right )^{\binom{N}{2}-L}$
- 相似之处
In [1]:
#用random_graphs.erdos_renyi_graph(n,p)方法生成一个含有n个节点、以概率p连接的ER随机图
%matplotlib inline
import networkx as nx
import matplotlib.pyplot as plt
ER = nx.random_graphs.erdos_renyi_graph(2000, 0.001) # 随机生成15个节点,节点间的连接概率都是0.2
#pos = nx.circular_layout(ER) # 图形样式,这里是节点在同心圆上分布
pos = nx.spring_layout(ER) # 图形样式,这里是节点在同心圆上分布
nx.draw(ER, pos, with_labels=False, node_size=40)
plt.show()

2.3 随机网络的性质¶
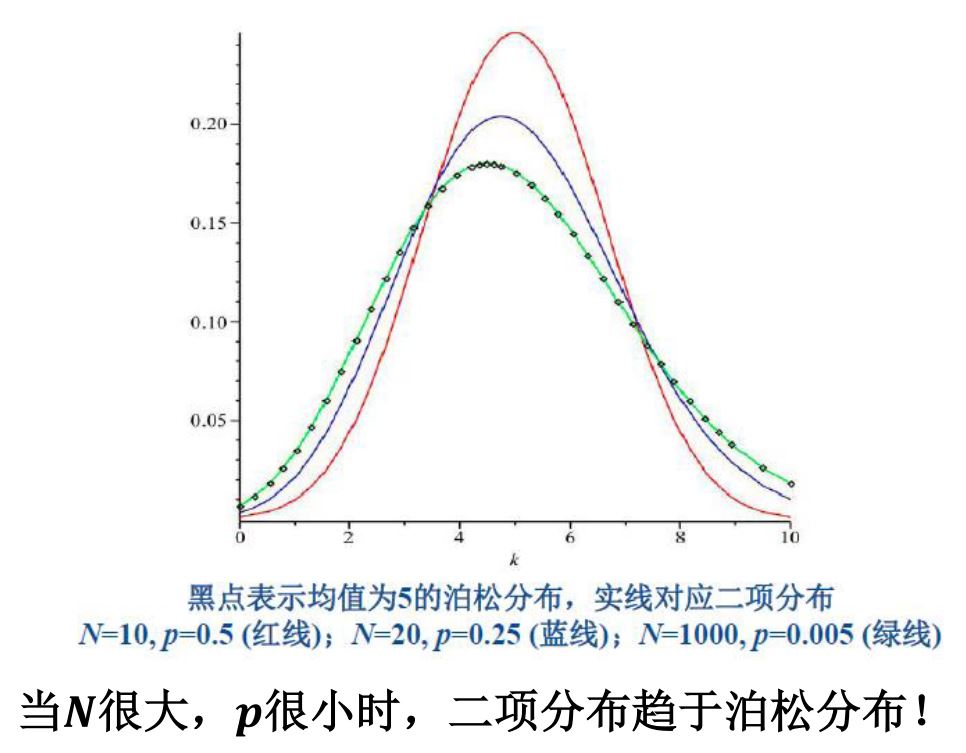
- 度分布
- 在计算节点度分布时,我们记节点$v$的度为$d$的概率为$P(d_v=d)$
- 对于由$G(N,p)$生成的图而言,这个概率是 $P\left ( d_{v}=d \right )=\binom{N-1}{d}p^{d}\left ( 1-p \right )^{N-1-d}$
- 这是一个二项分布,其极限是一个泊松分布$\lambda=Np$;泊松分布当$\lambda$很大时,接近正态分布
- 聚类系数
- 在随机图$G(N,p)$中,聚类系数等于概率$p$
- 平均路径长度
- 随机图的平均路径长度是 $l\approx \frac{ln\left | V \right |}{lnc}$
- 评价
- 较好的模拟平均路径长度
- 度分布不符合幂律分布
- 严重低估聚类系数
3. 小世界网络¶
- 真实世界的网络特征:小世界(六度分隔,平均距离小)、小团体(朋友之间也是朋友,聚类系数大)
- 规则网络与随机网络都不能满足要求。
- 能否融合规则网络与随机网络的特点,比如:在规则网络上加一些随机边?
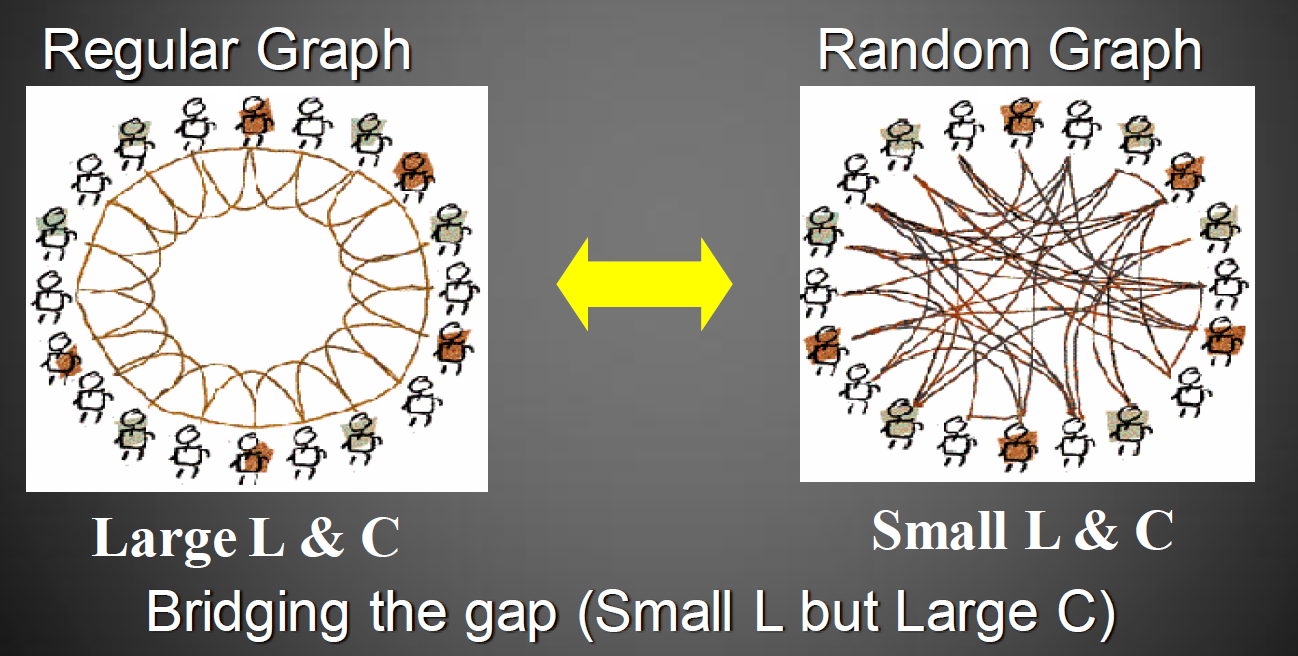
- 什么是WS小世界模型
- 1998年6月,博士生Watts和导师Strogatz发表在《Nature》上。
- 从规则网络开始:含有$N$个节点的最近邻居网络,它们围成一个环,其中任何一个节点与它左右相邻的各$c/2$个节点相连,$c$是偶数;
- 随机化重连:以概率$p$随机重连网络中原有的每条边,即把每条边的一个端点保持不变,另一个端点改为取网络中随机选择的一个节点。
- 调节重链参数$p$可以从规则向随机网络过渡。
- 该模型称为WS小世界模型,能够表现出小世界性质:平均路径长度较短、聚类系数较高
In [6]:
#用random_graphs.watts_strogatz_graph(n, k, p)方法生成一个含有n个节点、每个节点有k个邻居、以概率p随机化重连边的WS小世界网络
import networkx as nx
import matplotlib.pyplot as plt
WS = nx.random_graphs.watts_strogatz_graph(200, 4, 0.1)
# pos = nx.circular_layout(WS) # 图形样式,这里是节点在一个圆环上均匀分布
pos = nx.spring_layout(WS) # 图形样式,这里是节点在一个圆环上均匀分布
nx.draw(WS, pos, with_labels=False, node_size=40)
plt.show()

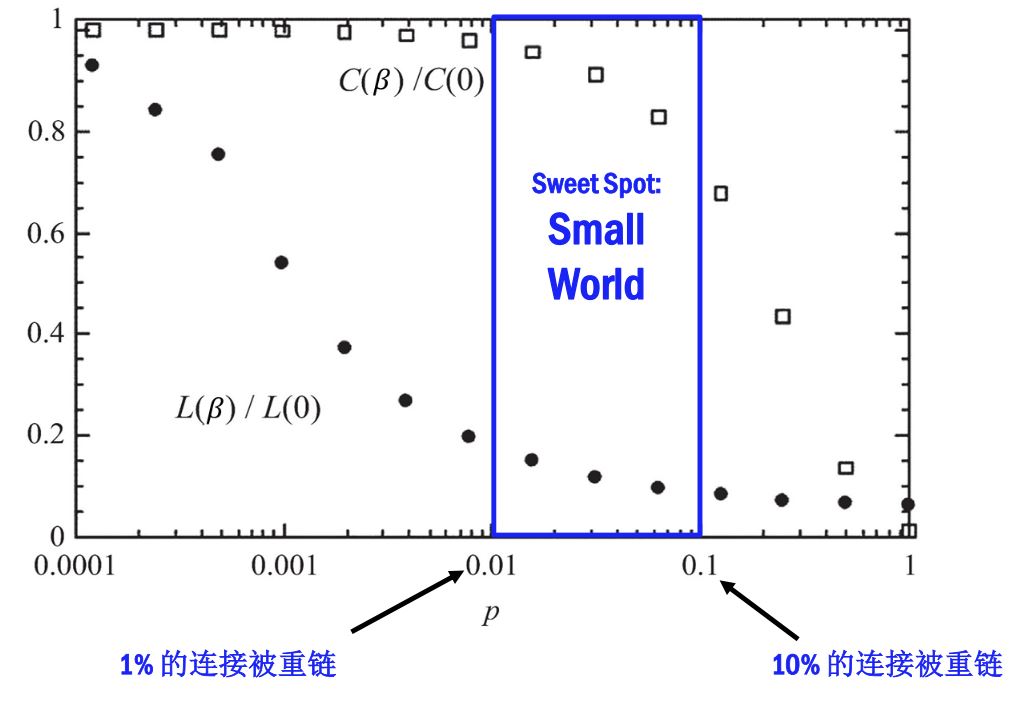
- 小世界网络聚类系数和平均路径长度随重链参数 $p$ 变化情况如下图
- 横坐标为重链参数$p$
- 纵坐标为系数与规则网络系数的比例。
- $p$在0.01和0.1之间时,更像小世界网络。
- 评价
- 比较接近现实的聚类系数
- 较短的平均路径长度
- 度分布仍不满足幂律分布

4.2 无标度网络的生成过程¶
- 始于包含$m_0$个节点的小图(不能是空图,可以取为完全图),然后逐渐加入新的节点,直到加满$N$个节点为止
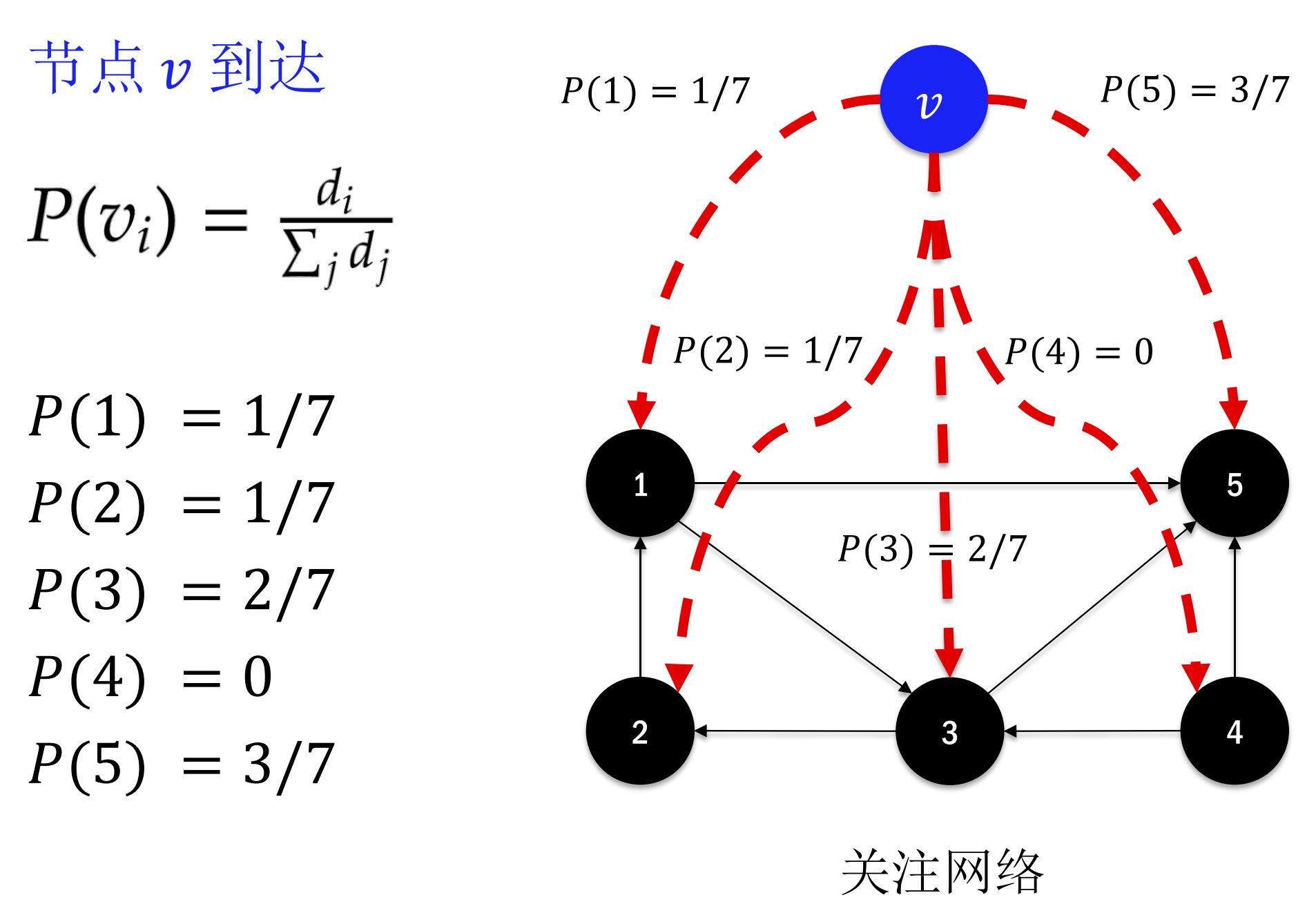
- 与现有节点$v_i$的连接按如下概率进行$$P\left ( v_{i} \right )=\frac{d_{i}}{\sum_{j}d_{j}}$$
- 示例:
In [3]:
#用random_graphs.barabasi_albert_graph(n, m)方法生成一个含有n个节点、每次加入m条边的BA无标度网络
import networkx as nx
import matplotlib.pyplot as plt
BA = nx.random_graphs.barabasi_albert_graph(4000, 1)
pos = nx.spring_layout(BA) # 图形的布局样式,这里是中心放射状
nx.draw(BA, pos, with_labels=False, node_size=40)
plt.show()

4.3 无标度网络的性质¶
- 度分布
- BA模型生成的网络符合幂律分布$p\left ( k \right )=ck^{-\lambda }$
- 其中指数$\lambda =2.9\pm 0.1$
- 真实世界网络的指数会在一个区间内变动,但BA模型的指数变化幅度有限
- 聚类系数
- BA模型生成的网络并不能构造很多三角关系环
- BA模型的期望聚类系数可按照如下公式进行计算$C=\frac{m_{0}-1}{8}\cdot \frac{\left ( ln n \right )^{2}}{n}$
- 随着节点数量的增多,聚类系数越来越小,最终趋于0
- 平均路径长度
- BA模型生成的网络的平均路径长度随着网络中节点数的增长呈对数级增长$l\sim \frac{ln\left | V \right |}{ln\left ( ln\left | V \right | \right )}$
- BA模型比随机图模型生成的网络平均路径长度要短
- 评价
- 度分布满足幂律分布
- 较短的平均路径长度
- 聚类系数较低
Homework¶
- 思考:如何构造一个更接近现实生活的网络呢?
- 造数据是非常困难的事情。
谢谢大家!