- 社交网络与文本分析课程
7. 自动写作及初级神经网络模型
刘跃文 教授、博导西安交通大学 管理学院
联系方式: liuyuewen@xjtu.edu.cn2023年4月16日 版本1.3
1. 自动写作的基本原理¶
1.1 应用场景¶
- 写作是运用语言文字符号反映客观事物、表达思想感情、传递知识信息的创造性脑力劳动,可分解为立意、素材搜集、创作输出三大步骤。
- 自动写作是指人工智能算法自主完成写作任务,在写作过程中不需要人工干预。当前计算机已经能够自动撰写数据新闻、热点新闻、投研报告、联想式新闻等类型。
结构化数据新闻写作
- 通常以结构化数据为输入,智能写作算法按照人类习惯的方式描述数据中蕴含的主要信息
- 由于机器对数据的处理速度远超人类,因此非常擅长完成时效性新闻的报道任务
- 典型例子:财经快讯、地震快讯、体育战报、天气预报等
热点新闻写作
- 通常以海量素材为基础,按照应用需求线索(例如事件、人物等)筛选合适的内容,并基于对内容的分析抽取关注的信息,最后按照写作逻辑组织为篇章结果
- 由于机器能够快速处理海量数据,因此非常擅长挖掘大数据中蕴含的分布、关联等信息
- 典型例子:热点组稿、事件脉络、排行盘点等
投研报告写作
- 机器基于充分的训练数据,训练模型并得到创作能力,可以根据人类的指令,产出符合特定格式要求的分析报告
- 典型例子:公司股票研报等
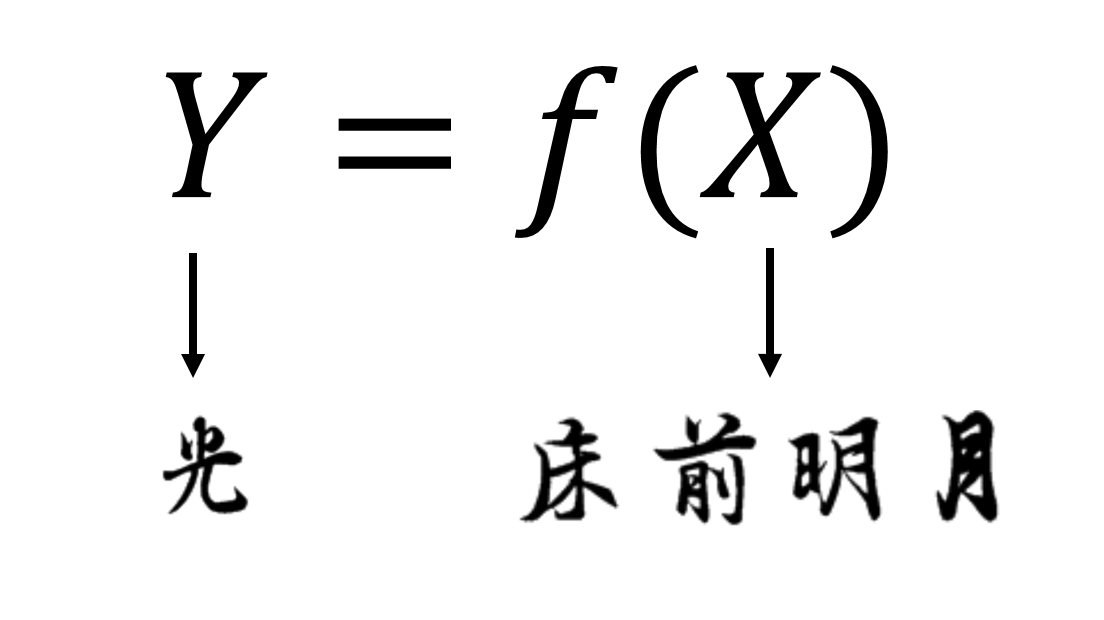
案例:逻辑回归“写诗”¶
- 读入数据
- 数据预处理
- 去掉诗的题目以及空格
- 为了预测第一个字,将每首诗前面补充bbb
- 数据整理:
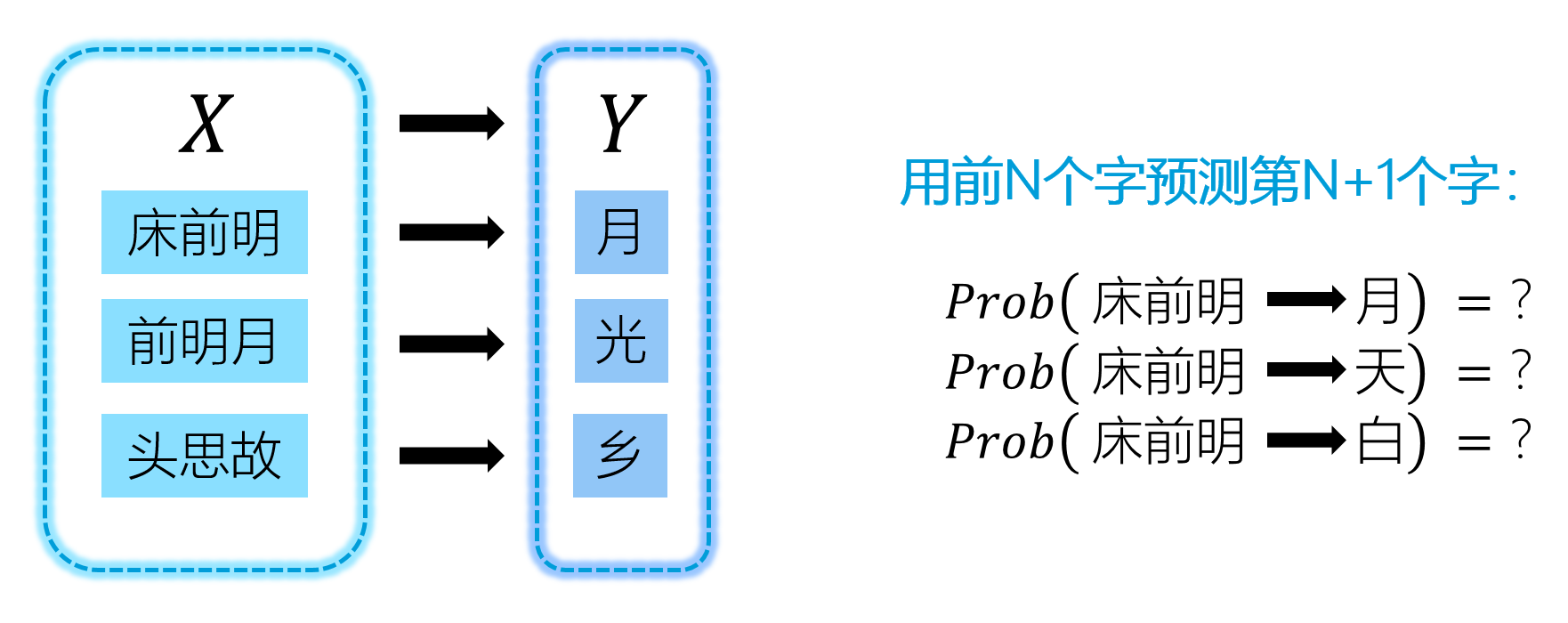
- 生成X和Y:将一首诗中的每个字分别看成Y,将Y前面的三个字看成X1,X2,X3
- 文字编码:由于文字是非结构化数据,不能在计算机中直接分析,因此对文字进行编码处理

# 使用pandas读入数据
import pandas as pd
poems_text = pd.read_table('data/poems_clean.txt', header=None)
poems_text.columns = ["text"]
# 查看文本
print(poems_text.head())
print(poems_text.shape)
# 去除题目、空格
import string
import numpy as np
poems_new = []
for line in poems_text['text']: # poems_text[0]的第0列,指
title, poem = line.split(':')
poem = poem.replace(' ', '') #将空格去掉
poem = 'bbb' + poem
poems_new.append(list(poem))
print(len(poems_new))
# 生成X和Y的矩阵
XY =[]
for poem in poems_new:
for i in range(len(poem) - 3):
x1 = poem[i]
x2 = poem[i+1]
x3 = poem[i+2]
y = poem[i+3]
XY.append([x1, x2, x3, y])
# 展示整理后的X和Y的形式
print("原始诗句:")
print(poems_text['text'][3864])
print("\n")
print("训练数据:")
print(["X1", "X2", "X3", "Y"])
for i in range(132763, 132773):
print(XY[i])
# 文字编码
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(poems_new)
print(tokenizer.word_index)
#tokenizer默认把0这个索引留给停止词了,其它的词是从1开始索引的。然后分类的损失又默认0是第一类
#所以导致假设我们有三个字:a,b,c。他们的索引分别是1,2,3,没有0。这对keras要使用一个4分类才行
vocab_size = len(tokenizer.word_index) + 1
print(vocab_size)
XY_digit = np.array(tokenizer.texts_to_sequences(XY))
X_digit = XY_digit[:, :3]
Y_digit = XY_digit[:, 3]
for i in range(132763, 132773):
print("{:<35}".format(str(XY[i])), "\t", "{:<30}".format(str(list(X_digit[i]))),"\t", Y_digit[i])
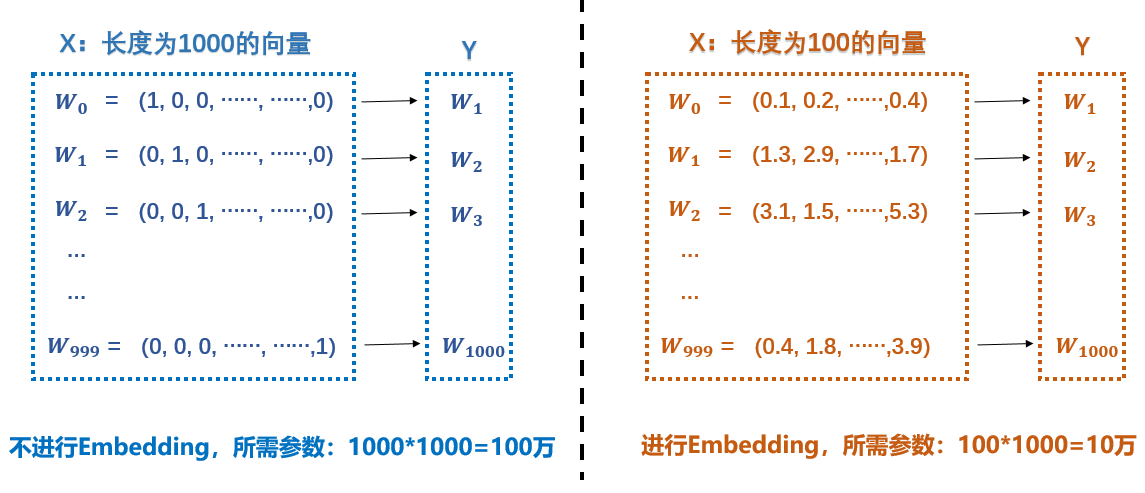
# Embedding + 线性模型
from tensorflow.keras.layers import Input, Embedding
from tensorflow.keras.models import Sequential, load_model, Model
from tensorflow.keras.layers import Input, Dense, Activation, Embedding, Flatten
hidden_size = 300
inp = Input(shape=(3,))
x = Embedding(vocab_size, hidden_size)(inp)
x = Flatten()(x)
x = Dense(vocab_size)(x)
pred = Activation('softmax')(x)
lstm_model = Model(inp, pred)
lstm_model.summary()
# 训练模型
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X_digit,Y_digit,test_size=0.2, random_state=0)
from tensorflow.keras.optimizers import Adam
lstm_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.001))
lstm_model.fit(X_train, Y_train, validation_data=(X_test, Y_test), batch_size=1000, epochs=1)
lstm_model.save('CNNPoem' + 'Model')
# model.save_weights('CNN.h5') # 文件类型是HDF5
# 模型效果检验
from tensorflow.keras.models import load_model
model = load_model('CNNPoem' + 'model')
# model.load_weights('CNN.h5')
sample_text = ['白', '日', '依']
print(sample_text)
sample_index = tokenizer.texts_to_sequences(sample_text)
print(sample_index)
word_prob = model.predict(np.array(sample_index).reshape(1, 3))[0]
print(tokenizer.index_word[word_prob.argmax()], word_prob.max())
# 模型应用
poem_incomplete = 'bbb风****花****雪****月****'
poem_index = []
poem_text = ''
for i in range(len(poem_incomplete)):
current_word = poem_incomplete[i]
if current_word != '*':
# 给定的词
index = tokenizer.word_index[current_word]
else:
# 根据前三个词预测 *
x = poem_index[-3:]
y = model.predict(np.expand_dims(x, axis=0))[0]
index = y.argmax()
current_word = tokenizer.index_word[index]
poem_index.append(index)
poem_text = poem_text + current_word
poem_text = poem_text[3:]
print(poem_text[0:5])
print(poem_text[5:10])
print(poem_text[10:15])
print(poem_text[15:20])
逻辑回归(CNN)模型写诗,缺点?¶
静夜思:床前明月光,疑似地上霜,举头望明月,低头思故乡
输入长度必须固定(例如:X=明,月,光)!问:能否长度任意?
输入没有记忆(例如:X=前,明,月;床?去哪里了?)!问:能否对历史有记忆!
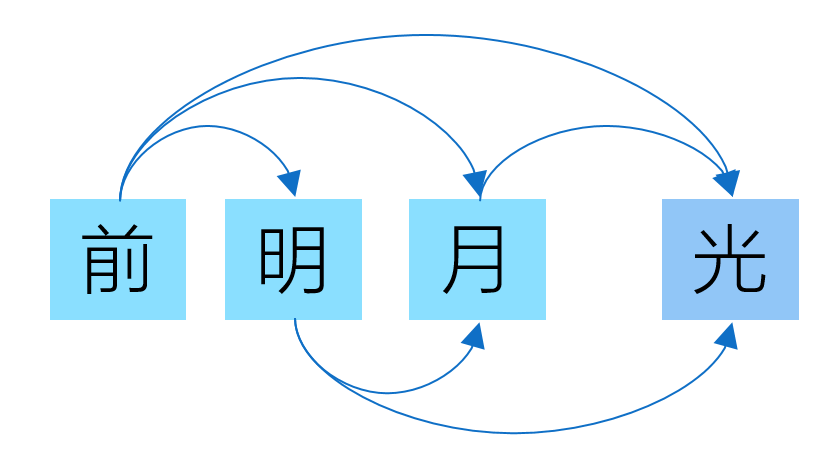
状态空间模型¶
- 静夜思:床前明月光,疑似地上霜,举头望明月,低头思故乡
RNN:更好的处理“序列数据”¶
RNN(Recurrent Neural Network),也叫循环神经网络,是一种专门处理“文本序列数据”的方法。
核心思想:通过将历史信息不断保留与传递,而保留与传递的载体就是状态$Z_t$。
RNN最早被认知科学与计算神经科学的研究人员提出并应用,后来被广泛应用于研究序列数据,下图展示了一些早期的RNN相关文献。

3.2 RNN的基本原理¶
- 传统的BP神经网络结构
- 数据输入——输出彼此相互独立
- 每次的训练过程中只会进行网络连接权重的调整,具体的网络输出并不会影响下一次的网络输入信号
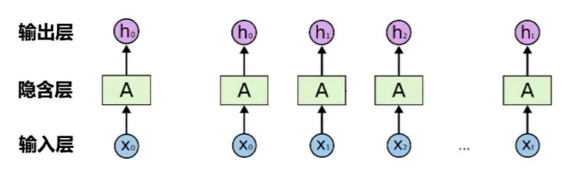
- Recurrent Neural Networks
- 文本是非常典型的序列数据,后续文本内容显然和前导文本内容之间存在语义关联,而传统的神经网络模型并不能匹配这一数据特征
- 期望:分类器能够记得上下文的内容并用于预测 -特别是将上文内容用于预测
- RNN是包含循环的神经网络,允许原有输入信息的持久化
- 因此RNN是对应文本这种序列类数据的最自然的神经网络架构
RNN结构¶
当前时刻的数据 + 上一时刻的状态 = 当前时刻的状态
每一次神经网络的判断过程之后,都会把信息传给下一次判断过程,就类似于我们人脑的思考理解过程
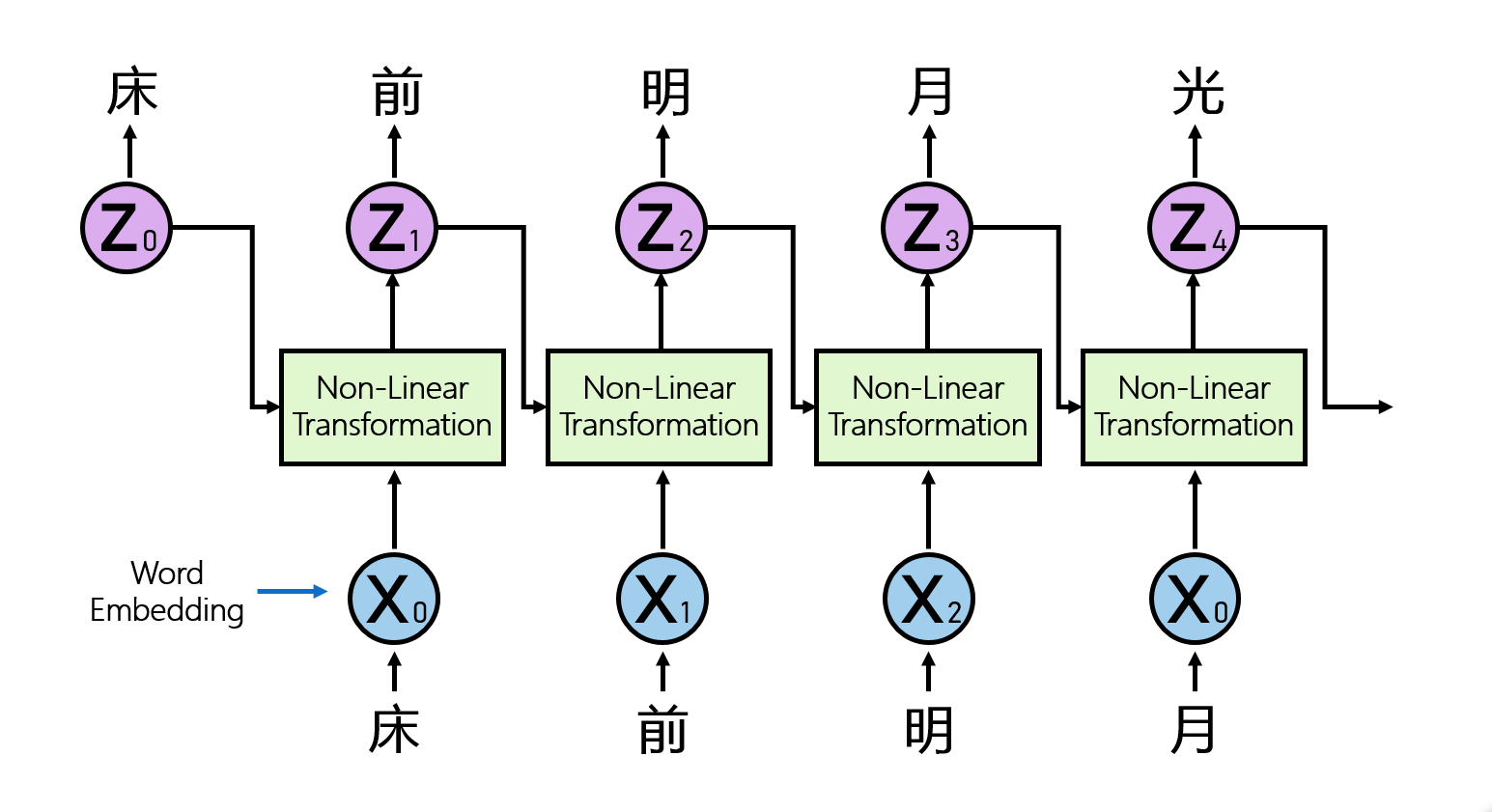
- 非线性变换:$Z_{t+1}=f(W_1X_t,W_2Z_t)$。问题:(1)可以考虑什么样的非线性变幻?(2)消耗多少个参数?
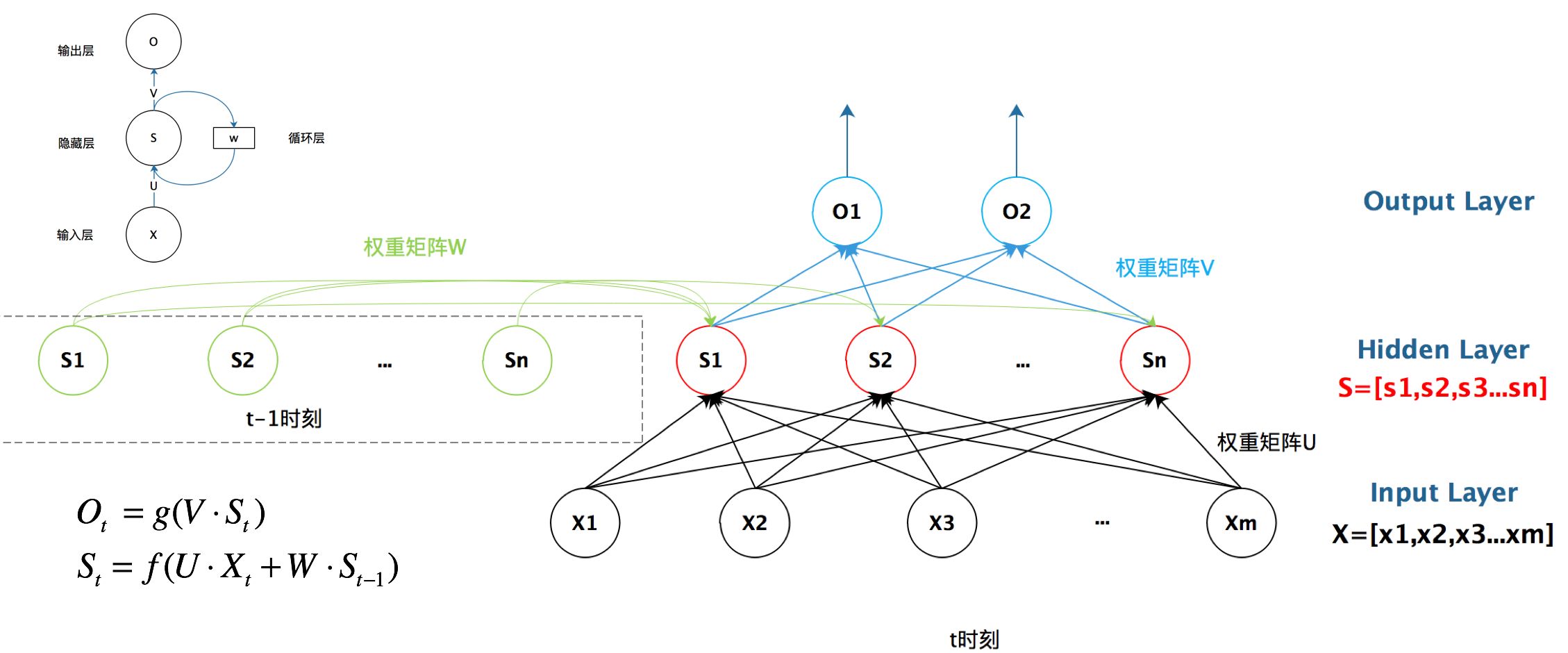
RNN的结构与参数量计算¶
- 从Input到Hidden: InputHidden+hiddenhidden+hidden
- 从Hidden到Output:Hidden*Output+Output
- 值得注意的是,文本分析还存在Input到embedding:Input*Embedding;上面讲的Input则变为embedding
# 数据的读入与展示
import string
import numpy as np
f = open('data/poems_clean.txt', "r", encoding='utf-8')
poems = []
for line in f.readlines():
title, poem = line.split(':')
poem = poem.replace(' ', '') #将空格去掉
poem = poem.replace('\n', '') #将换行符去掉
poems.append(list(poem))
print(poems[0][:])
# 数据整理:文字编码
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
tokenizer.fit_on_texts(poems)
poems_digit = tokenizer.texts_to_sequences(poems)
vocab_size = len(tokenizer.word_index) + 1 #加上停止词0
vocab_size #有多少个不同的字
数据整理¶
- 由于每首诗的长度不一致,为了将所有的诗放在一个统一的$m\times n$维数组中,我们需要在较短诗的末尾用0进行补齐

- 对齐$X$和$Y$:将每首诗的前一个字作为$X$,后一个字作为$Y$,进行数据对齐
#补全数据:为了将所有的诗放在一个M*N的np.array中,将每一首诗补0到同样的长度
poems_digit = pad_sequences(poems_digit, maxlen=50, padding='post')
print("原始诗歌")
print(poems[3864])
print("\n")
print("编码+补全后的结果")
print(poems_digit[3864])
# 对齐X和Y
X = poems_digit[:, :-1]
Y = poems_digit[:, 1:]
print(poems_digit.shape)
print(X.shape)
print(Y.shape)
print("X示例", "\t", "Y示例")
for i in range(10):
print(X[0][i], "\t", Y[0][i])
print("...", "\t", "...")
# 把$Y$变成One-Hot向量
print(vocab_size)
from tensorflow.keras.utils import to_categorical
Y = to_categorical(Y, num_classes=vocab_size)
print(Y.shape)
# 确定空间维度
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, SimpleRNN, Dense, Embedding, Activation, BatchNormalization
embedding_size = 100
hidden_size = 200
# 构建RNN模型
inp = Input(shape=(49,))
# Encoder
x = Embedding(vocab_size, embedding_size, mask_zero=True)(inp)
x = SimpleRNN(hidden_size,return_sequences=True)(x)
# prediction
x = Dense(vocab_size)(x)
pred = Activation('softmax')(x)
model = Model(inp, pred)
model.summary()
参数个数的计算¶
- vocab_size=5546; embedding_size=64; hidden_size=128
- Embedding: 5546*64 = 354944
- RNN:128*64 +128*128+128 = 24704
- Dense: 5546*128+5546=715434
# 模型训练
from tensorflow.keras.optimizers import Adam
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['accuracy'])
model.fit(X, Y, epochs=1, batch_size=200, validation_split=0.2)
model.save('RNNPoem' + 'Model')
# 模型应用
from tensorflow.keras.models import load_model
model = load_model('RNNPoem' + 'model')
poem_incomplete = '床****疑****举****低****'
poem_index = []
poem_text = ''
for i in range(len(poem_incomplete)):
current_word = poem_incomplete[i]
if current_word != '*':
index = tokenizer.word_index[current_word]
else:
x = np.expand_dims(poem_index, axis=0)
x = pad_sequences(x, maxlen=49, padding='post')
y = model.predict(x)[0, i]
y[0] = 0 #去掉停止词
index = y.argmax()
current_word = tokenizer.index_word[index]
poem_index.append(index)
poem_text = poem_text + current_word
poem_text = poem_text[0:]
print(poem_text[0:5])
print(poem_text[5:10])
print(poem_text[10:15])
print(poem_text[15:20])

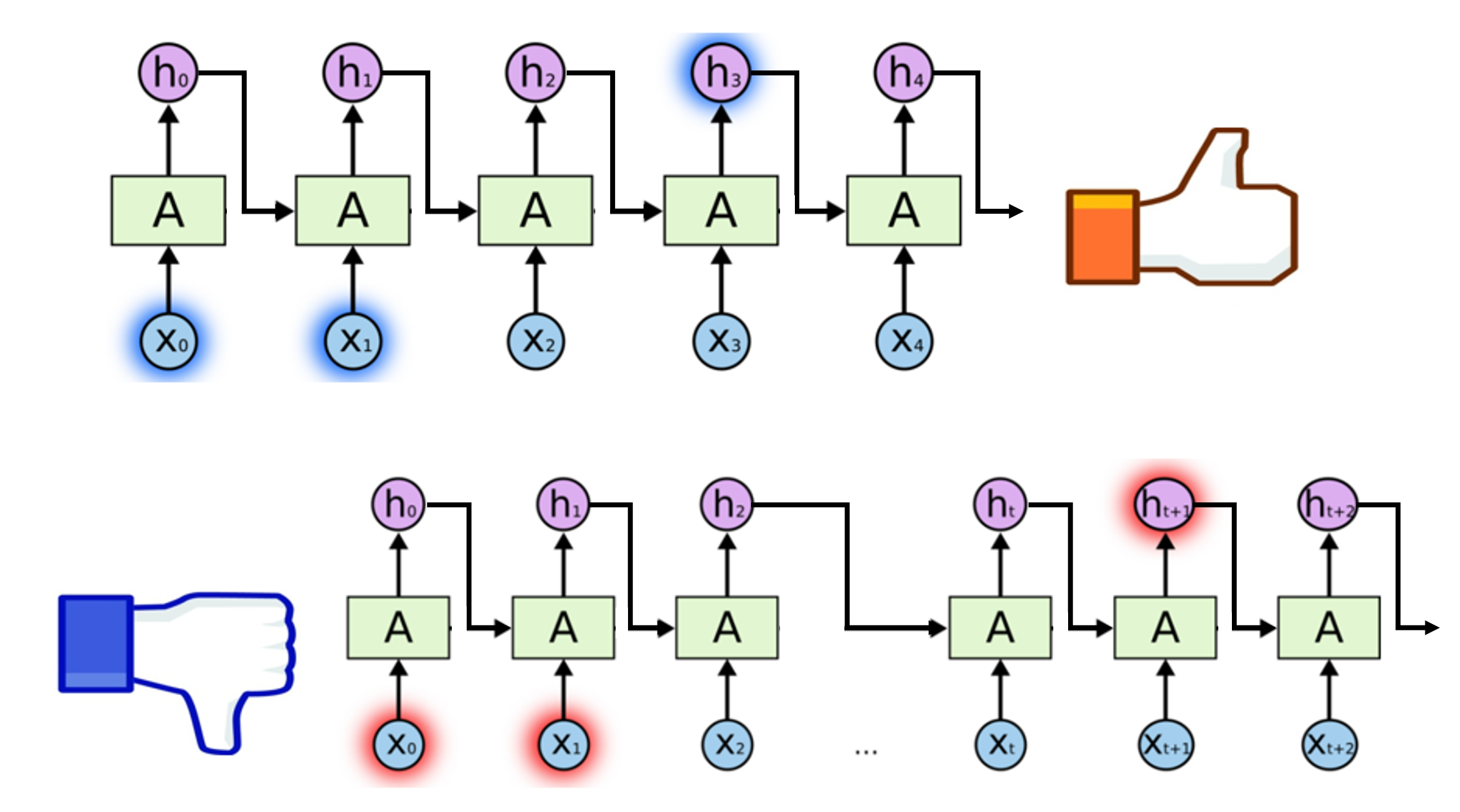
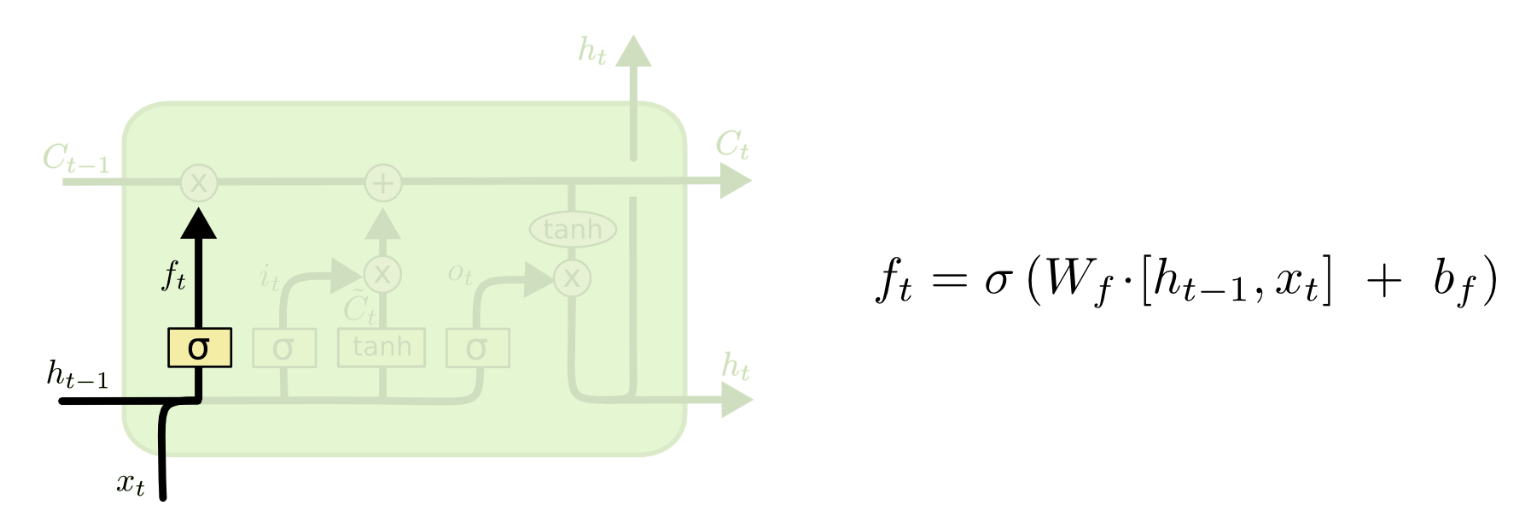
RNN存在的问题¶
- 如果让RNN完成上面的题目,它可以很容易的猜出(1),但是猜不出(2)
- 这是因为RNN无法处理“长距离依赖”(Long-Term Dependencies)
- RNN的这一短板是由于其算法导致:在训练RNN模型时,每步的梯度随距离会明显减弱,因此当距离过长时,迅速减小的梯度无法将之前的信息传递过去
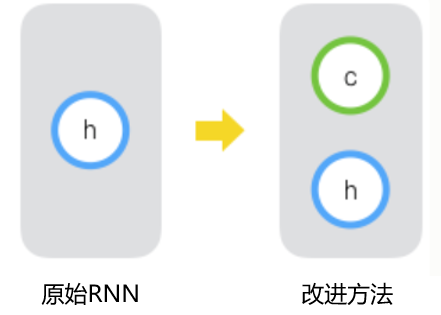

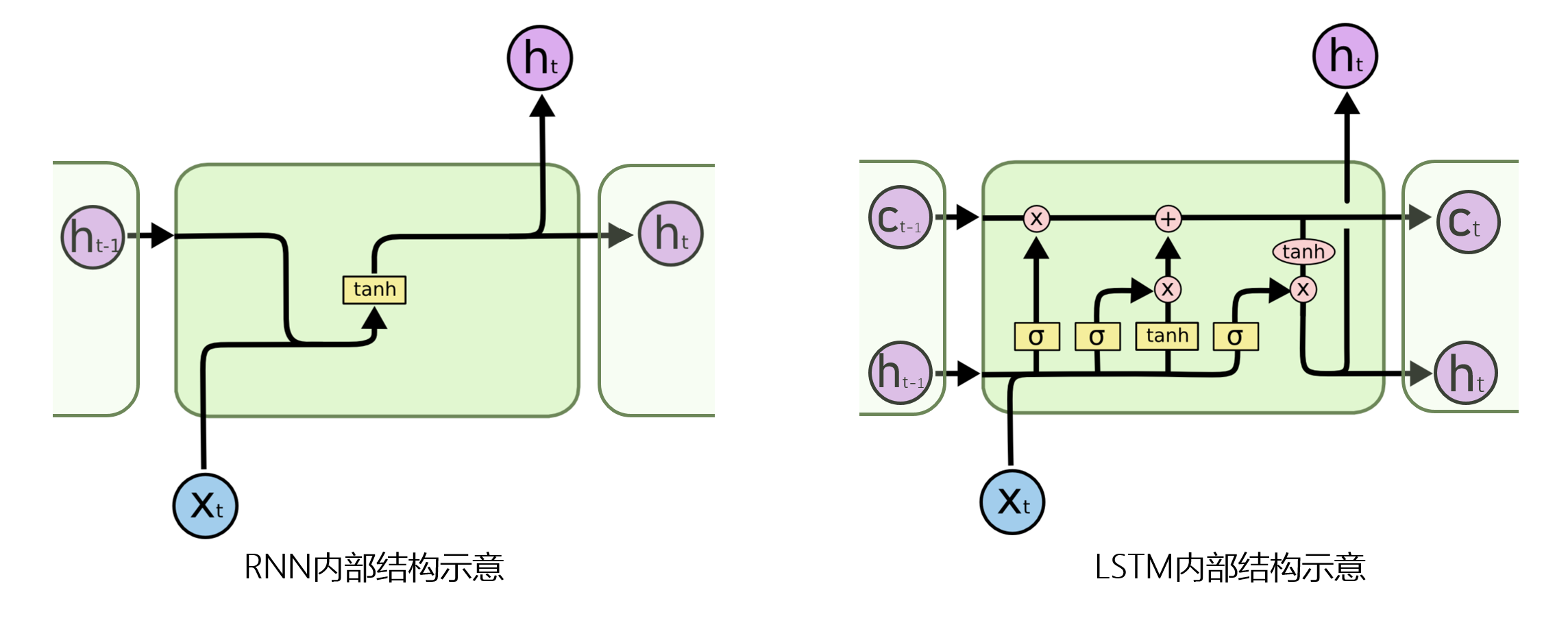

预备知识¶
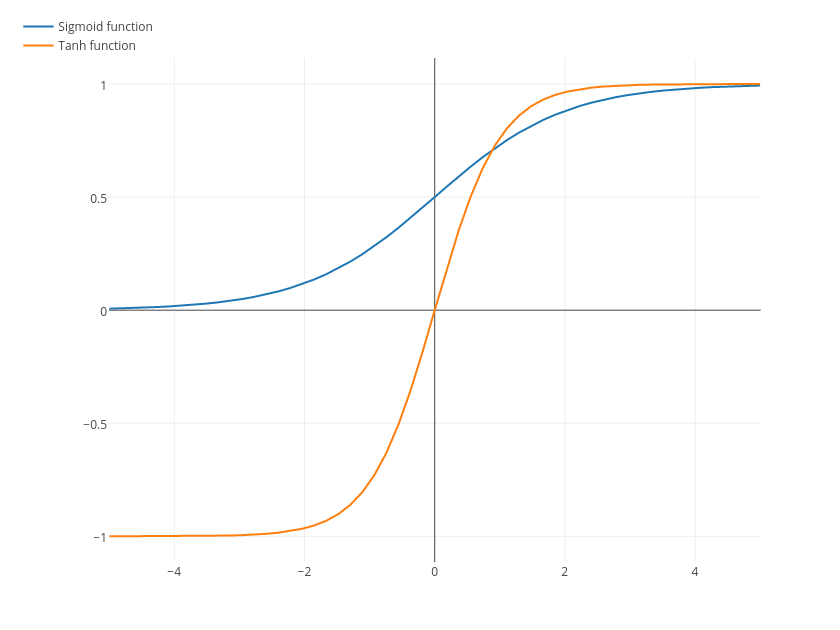
$\tanh$ 变换¶
- $\tanh$ 也是常用的非线性激活函数,可以将一个实数映射到 $(-1,1)$ 的区间,其数学表达式如下:
- $$\tanh x = \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}$$
- 与 sigmoid 不同的是,$\tanh$ 是0均值的, 而且 sigmoid 函数在输入处于0附近时,函数值变化比 $\tanh$ 敏感,一旦接近或者超出区间就失去敏感性,处于饱和状态
sigmoid 变换¶
- sigmoid 函数也叫 Logistic 函数,是神经网络中常用的非线性激活函数,可以将一个实数映射到 $(0,1)$ 的区间,其数学表达式如下: $$\sigma(x) = \frac{1}{1+e^{-x}}$$
两种变换的效果图¶
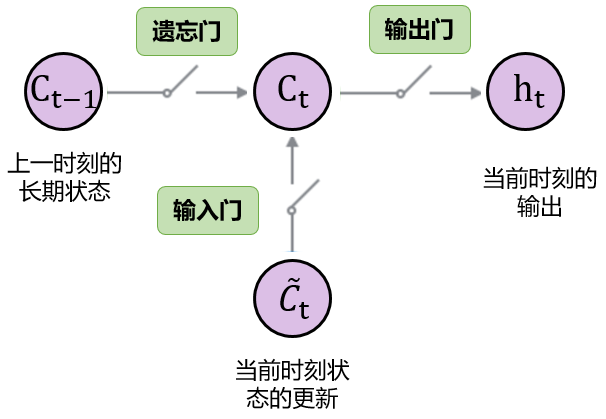
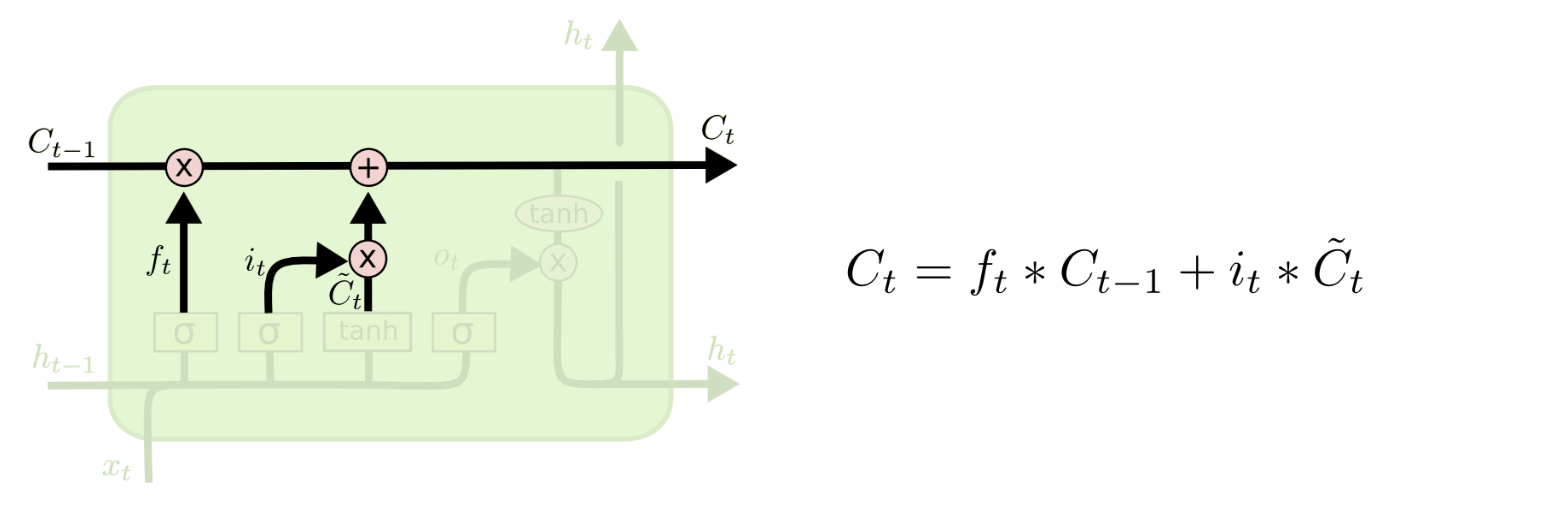
输入门(Input Gate)¶
- 输入门将决定对下一时刻的状态加入多少“新信息”
它由两层结构组成:前面的sigmoid layer将决定我们更新数据中的哪几个值,后面的tanh layer则会对数据中所有值输出更新值向量$\tilde{C_t}$。
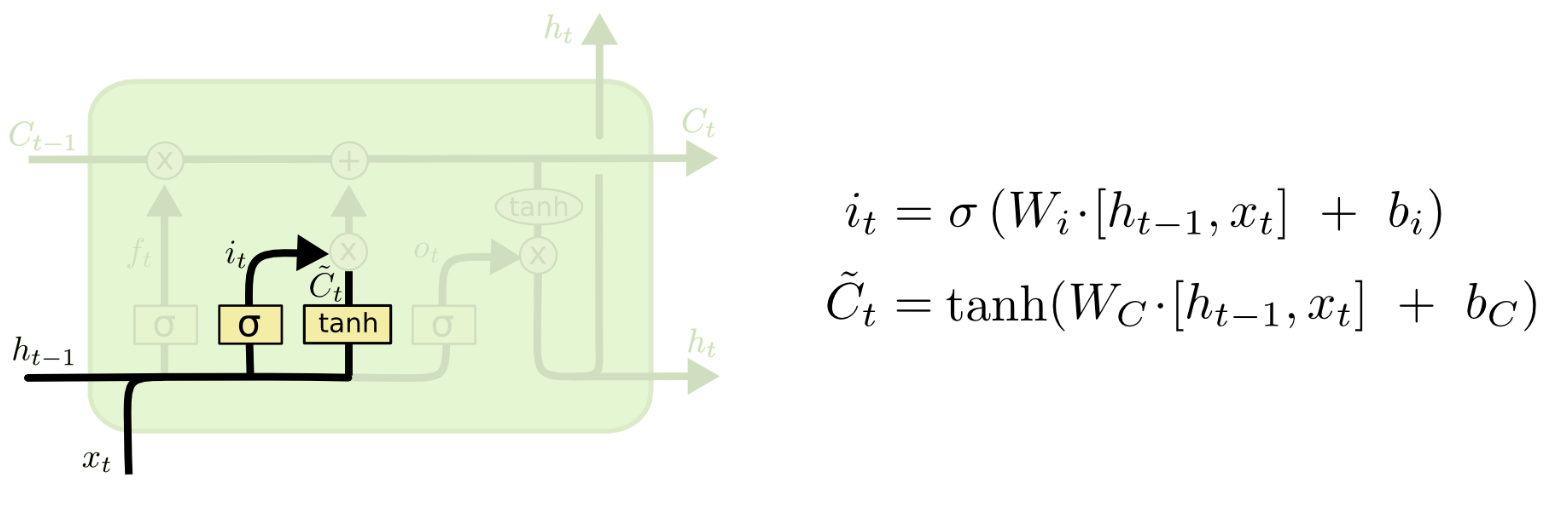
经过上面两步,可以计算当前时刻的长期状态$C_t$
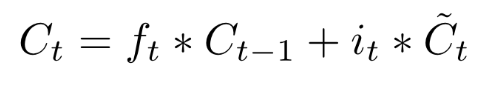
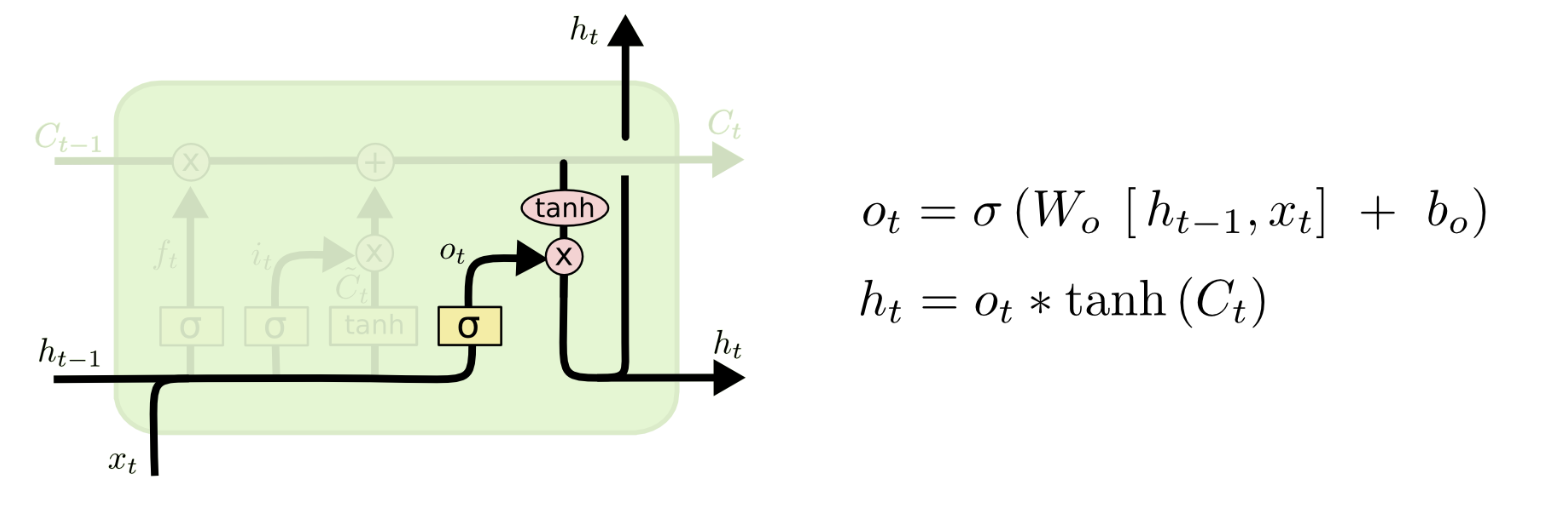
输出门(Output Gate)¶
- 输出门将决定单元的输出值$h_t$。
- 它同样由两层结构组成:前面的sigmoid layer将决定我们输出数据中的哪部分值,同时长期状态$C_t$将通过tanh layer转换至$-1$至$1$之间,最后的输出结果为两者的乘积。
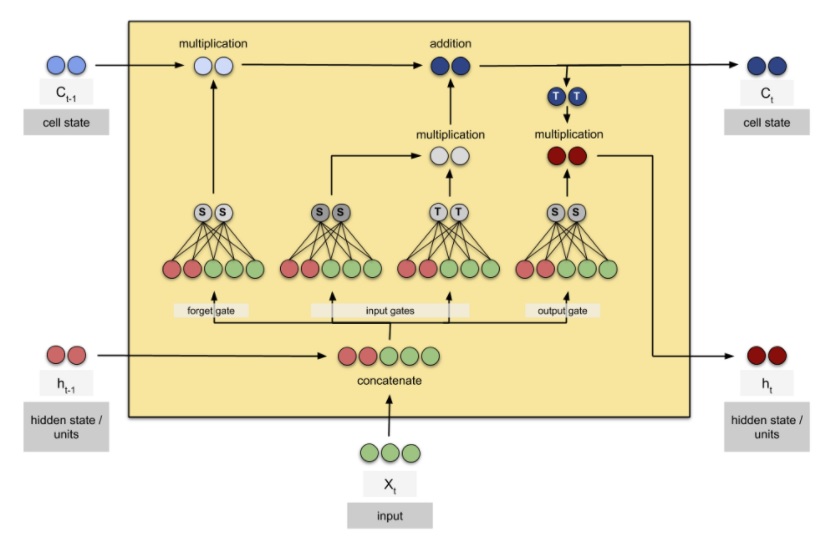
LSTM的展开和参数量计算¶
# 数据的输入与展示
import string
import numpy as np
f = open('data/poems_clean.txt', "r", encoding='utf-8')
poems = []
for line in f.readlines():
title, poem = line.split(':')
poem = poem.replace(' ', '') #将空格去掉
poem = poem.replace('\n', '') #将换行符去掉
poems.append(list(poem))
print(poems[0][:])
# 数据整理:文字编码,读入数据并使用`keras`中的`Tokenizer`为我们的语料库建立词典,给每个字分配一个索引。
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
tokenizer.fit_on_texts(poems)
vocab_size = len(tokenizer.word_index) + 1 #加上停止词0
poems_digit = tokenizer.texts_to_sequences(poems)
#为了将所有的诗放在一个M*N的np.array中,将每一首诗补0到同样的长度
poems_digit = pad_sequences(poems_digit, maxlen=50, padding='post')
# 数据整理:数据补全
print("原始诗歌")
print(poems[3864])
print("\n")
print("编码+补全后的结果")
print(poems_digit[3864])
# 生成X和Y
X = poems_digit[:, :-1]
Y = poems_digit[:, 1:]
print("X示例", "\t", "Y示例")
for i in range(10):
print(X[0][i], "\t", Y[0][i])
print("...", "\t", "...")
# 把Y变成One-Hot向量
from tensorflow.keras.utils import to_categorical
Y = to_categorical(Y, num_classes=vocab_size)
print(Y.shape)
# 构建LSTM的模型
# from keras.models import Model
from tensorflow import keras
from tensorflow.keras.layers import Input, LSTM, Dense, Embedding, Activation, BatchNormalization
from tensorflow.keras import Model
hidden_size1 = 300
hidden_size2 = 100
inp = Input(shape=(49,))
# Encoder
x = Embedding(vocab_size, hidden_size1, input_length=49, mask_zero=True)(inp)
x = LSTM(hidden_size2, return_sequences=True)(x)
# prediction
x = Dense(vocab_size)(x)
pred = Activation('softmax')(x)
model = Model(inp, pred)
model.summary()
数参数个数¶
Embedding层
- 我们一共有5546个字,每个字嵌入到一个128维的空间中,所以参数个数为:$5546\times 128=70988$。
LSTM层
第一、参考之前LSTM的介绍可以知道,需要参数估计的非线性变幻主要涉及到:$f_t$, $i_t$, $\tilde C_t$, 还有 $o_t$。每个非线性变化所消耗的参数一样。背后主要的原因是:TF要求$h_t$和$c_t$的维度一样(理论上完全可以不一样)。
第二、以$f_t$为例,它作用在$(h_{t-1},x_{t})$上面。由于$h_{t-1}$和$x_{t}$分别是一个64维和128维的向量。加上截距项,需要64+128+1=193个参数。这些参数应用到遗忘门,帮助$C_t$状态更新的时候,需要消耗:193*64=12352个参数。
第三,因为,$f_t$, $i_t$, $\tilde C_t$, 还有$o_t$一共4个非线性变换,而每一个变换所消耗的参数都是12352,因此,最终所需的所有参数是:$12352\times 4=49408$。
dense层
- 这是一个5546类的分类问题,输入就是h维度+常数项,所以参数个数为:$(64+1)\times 5546=360490$。
# 模型训练
from tensorflow.keras.optimizers import Adam
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.01), metrics=['accuracy'])
model.fit(X, Y, epochs=1, batch_size=1000, validation_split=0.2)
model.save('LSTMPoem' + 'Model')
# 应用模型
from tensorflow.keras.models import load_model
model = load_model('LSTMPoem' + 'model')
poem_incomplete = '风****花****雪****月****'
poem_index = []
poem_text = ''
for i in range(len(poem_incomplete)):
current_word = poem_incomplete[i]
if current_word != '*':
index = tokenizer.word_index[current_word]
else:
x = np.expand_dims(poem_index, axis=0)
x = pad_sequences(x, maxlen=49, padding='post')
y = model.predict(x)[0, i]
y[0] = 0 #去掉停止词
index = y.argmax()
current_word = tokenizer.index_word[index]
poem_index.append(index)
poem_text = poem_text + current_word
poem_text = poem_text[0:]
print(poem_text[0:5])
print(poem_text[5:10])
print(poem_text[10:15])
print(poem_text[15:20])
TensorFlow的安装¶
- 有能力的可以考虑lunix,或Win10新版本下的Lunⅸ环境
- 1.2版本之后开始支持 Window
- 要求 Python版本3.5 64位及以上
- CPU版本:pip3 install --upgrade tensorflow
- GPU版本:pip3 install --upgrade tensorflow-gpu
- 需要进一步安装CUDA和 cuDNN
- 安装测试
- import tensorflow as tf
- hello = tf.constant('Hello, TensorFlow!')
- print(tf.Session(). run(hello))
Keras的安装¶
- 依赖包
- numpy,scipy(注意版本依赖问题,不熟悉的直接让程序自动更新)
- pyyaml
- HDF5,h5py(可选,仅在模型的save/load函数中使用)
- 如果拟合CNN(卷积神经网络),推荐安装 cuDNN
- 后端框架
- TensorFlow
- Theano
- CNTK
- pip install keras -U --pre